Last week, Google announced the launch of Gemini 1.5, an updated version of its recently released Gemini 1.0 model.
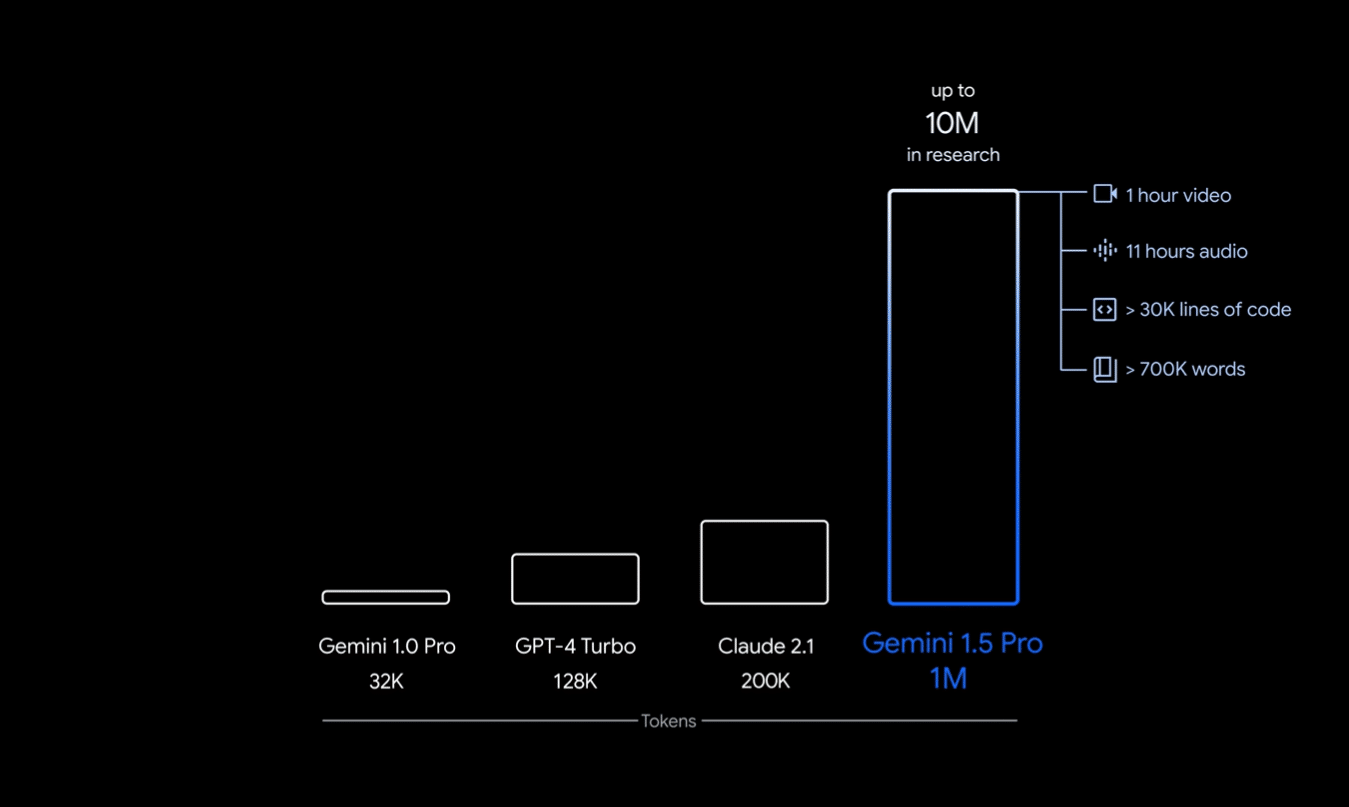
The model has the longest context window of any foundational model on the market, with the ability to process up to 1 million tokens in a single prompt. This makes it ideal for analyzing and summarizing larger volumes of text.
While Gemini 1.5 Pro is restricted to a 128,000 token context window, a limited group of developers and enterprise customers can use it with up to 1 million tokens via AI Studio and Vertex AI.
Key Takeaways
- Google has introduced Gemini 1.5, which has a remarkable capacity to process up to 1 million tokens for select users.
- This compares against Claude 2.1’s limit of 200,000 tokens or GPT-4’s maximum limit of 128,000 tokens.
- Gemini allows up to one hour of video, 11 hours of audio, 30,000 lines of code, or 700,000 words to form a prompt.
- Is the new arms race around tokens?
Compared to GPT-4’s 32,000 token limit, or 128,000 tokens for GPT-4 Turbo users, Google looks to be massively upping the maximum bounds of how much data a user can provide an LLM.
The million token volume means that Gemini 1.5 can process a single prompt consisting of either:
- 1 hour of video
- 11 hours of audio
- 30,000 lines of code
- 700,000 words
When considered alongside OpenAI’s release of the text-to-video model Sora on the same day, which can generate videos of up to 1 minute in length, it’s clear the multimodal AI arms race is heating up to unprecedented levels.
Where Does Gemini 1.5 Fit into the LLM Market?
The time of this release is surprising because it comes just one week after Google announced its rebrand of Bard and released its most powerful multimodal model, Gemini 1.0 Ultra.
At its core, Gemini 1.5 is a more powerful version of the Gemini Pro model used to power the Gemini chatbot that replaced Bard.
More specifically, 1.5 Pro outperformed 1.0 Pro on 87% of benchmarks Google uses to measure large language model (LLM) performance while performing at a similar level to 1.0 Ultra but using less compute resources.
This is impressive when considering that Ultra was the first model to outperform human experts on the Massive Multitask Language Understanding (MMLU) benchmark.
Google and Alphabet CEO Sundar Pichai explained in a post on X, “This next-gen model uses a Mixture-of-Experts (MoE) approach for more efficient training and higher-quality responses.”
What does an MoE approach entail? According to the CEO of Google DeepMind, Demis Hassabis, “while a traditional Transformer functions as one large neural network, MoE models are divided into smaller ‘expert’ neural networks.
“Depending on the type of input given, MoE models learn to selectively activate only the most relevant expert pathways in its neural network. This specialization massively enhances the model’s efficiency,” Hassabis said in the announcement blog post.
This architecture enables Gemini 1.5 to learn complex tasks more quickly and makes it easier to train. Yet the real selling point for the model is its larger context window. The ability to support up to 1 million tokens puts it far beyond even GPT-4 Turbo’s 128,000 limit.
In addition, the model also has the ability to process video content – with one demo showing the model analyzing plot points in Sherlock Jr. (1924), a 45-minute silent movie by Buster Keaton.
Google DeepMind Research Scientist Machel Reid said: “In one test, we dropped in an entire code base, and it wrote documentation for it, which was really cool.
“And there was another test where it was able to accurately answer questions about the 1924 film Sherlock Jr. after we gave the model the entire 45-minute movie to ‘watch.'”
The Multimodal AI Race
The release of Gemini 1.5 highlights that the multimodal AI race is taking place at a higher speed than ever before. For Google, it makes sense to strike while the iron’s hot and follow up on the release of Gemini quickly rather than wait for OpenAI to innovate.
Throughout 2023, Google was rapidly putting together a multimodal AI ecosystem. Back in May 2023, Pichai was already posting about developing a next-generation foundation model called Gemini, which was “created from the ground up to be multimodal.”
Then, in December, the tech giant announced the official launch of Gemini, which is available in three sizes: Ultra, Pro, and Nano. The Pro version of Gemini was initially integrated into Bard before the research assistant was finally rebranded to Gemini in February 2024.
In December, Google also debuted its text-to-image diffusion model Imagen 2, which laid the foundation for the image generation tool ImageFX, which was released in February. It also launched the text-to-music tool MusicFX.
OpenAI’s pursuit of multi-modality has been no less chaotic. After launching GPT-4 in March 2023, the AI lab announced the creation of GPT-4V in September, which gave ChatGPT the ability to analyze image inputs.
Then, in October, the company gave ChatGPT Plus and Enterprise subscribers access to image creation capabilities in ChatGPT with a DALL-E 3 integration.
Just a month later, in November, at the DevDay developer conference in San Francisco, the organization announced its GPT-4 Turbo model, as well as text-to-speech and the ability to create custom GPTs. In 2024, this was expanded further with the launch of the GPT Store in January and Sora in February.
At this stage, the focus appears to be incrementally incorporating multimodal capabilities into each vendor’s flagship models.
The Bottom Line
Continuous development is the key to staying on top in the multimodal AI market.
While OpenAI is still in the driver’s seat, the launch of Gemini 1.0 and Gemini 1.5 is gradually chipping away at this dominance.
Who will prevail long term will likely come down to who can innovate at this pace consistently — and consumers and businesses finding value in adding the tools to their workflow.