
In the world of large language models (LLMs), speed kills.
As the generative AI arms race wages on, California-based chip startup Qroq has rapidly been gaining traction for developing chips, known as language processing units (LPUs), that can run 10 times faster than traditional AI processing hardware.
Will Groq become a key enabler of AI model development in the future? Let’s see what it’s capable of today.
Key Takeaways
- Groq is an AI startup developing language processing units that can run AI inference 10 times faster than GPUs.
- Groq AI fits businesses that want to increase the speed of inference tasks while lowering their overall cost.
- The high inference speeds make Groq a key competitor against OpenAI.
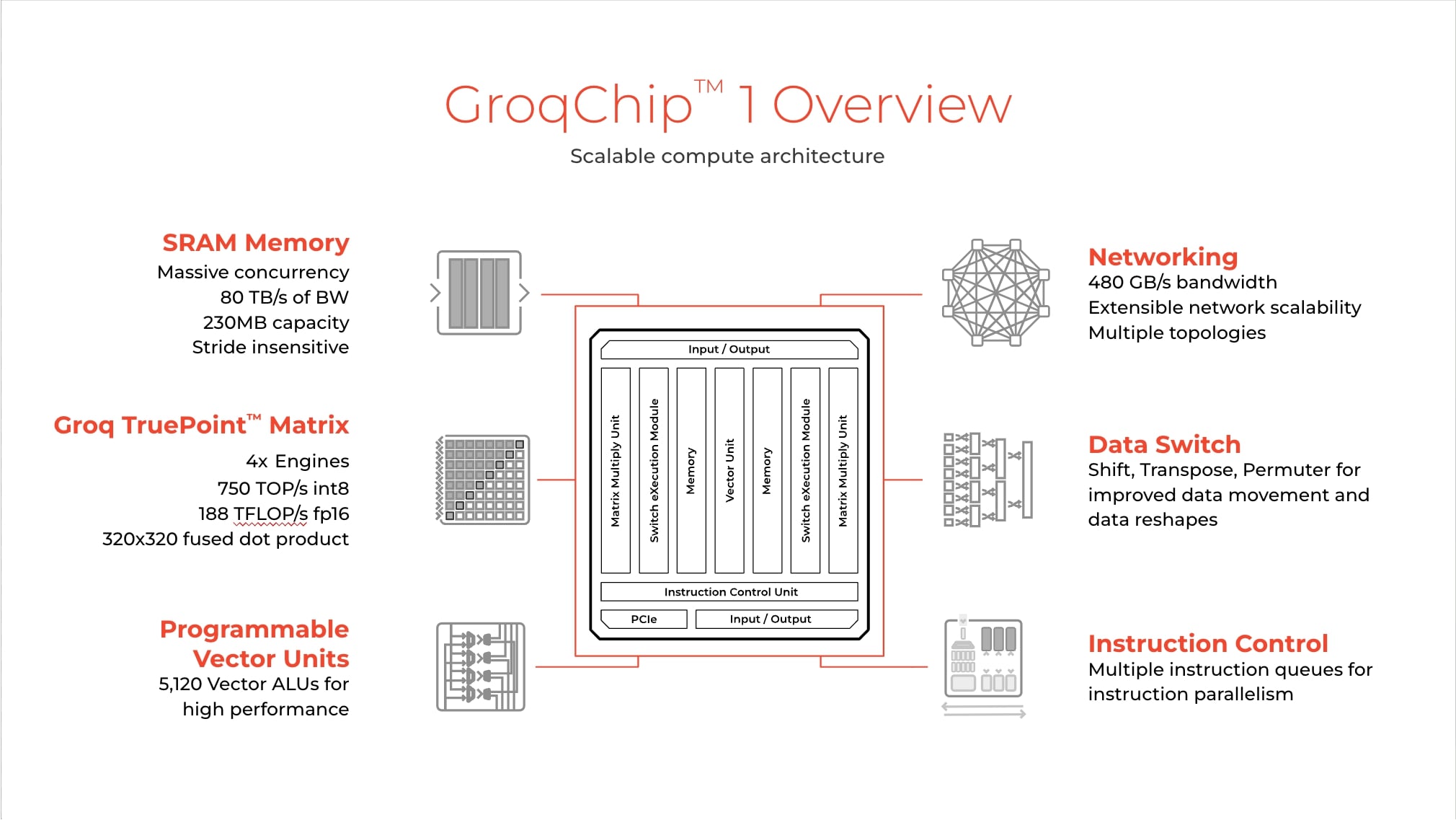
What is Groq & Why is Groq AI Important in 2024?
Groq is an AI chip founded in 2016 by CEO Johnathan Ross, which develops chips and an LPU inference engine designed to offer faster inference for generative AI models.
The inference engine acts as Groq AI’s chatbot interface, where users can enter prompts.
Before forming Groq, Ross worked as an engineer at Google. He helped the organization develop its popular tensor processing unit (TPU), an accelerator chip used to help train and run models.
This means it might be an ultimate choice for enterprises that want to increase the speed of inference tasks while lowering their overall cost.
These capabilities will only improve in the future as more Groq news emerges.
The startup is currently valued at $1 billion and has raised $367 million to date.
Groq vs. OpenAI
The high inference speeds offered by Groq make it a key competitor against OpenAI.
While it doesn’t produce its own LLM, it offers an infrastructure that can accelerate the performance of other third-party models.
The use of Groq and the higher compute capacity of its LPUs reduces the amount of time per word calculated. This means that text sequences can be created faster, and the overall cost of inference tasks is reduced.
For example, Groq can be combined with powerful open-source models like Llama 3 to offer responses that are on par with GPT-4 at extremely high speeds.
More specifically, Llama 3 paired with Groq reportedly achieved a throughput of 877 tokens per second on Llama 3 8B and 284 tokens per second on Llama 3 70B. In contrast, according to ArtificialAnalysis, GPT-4 has a throughput of 18.2 tokens per second.
In this sense, OpenAI’s slower inference speed may encourage organizations and developers to gravitate toward using Groq and its LPUs as a high-speed alternative.
Is It Cheap to Use Groq AI?
Using Groq is cost-effective when using language models, including Llama 3 (8B and 70B), Mixtral 8x7B SmoE, and Gemma 7B.
The pricing, according to Groq, is as follows:
| Model | Speed | Price per 1 million tokens |
|---|---|---|
| Llama 3 70B (8K context length) | ~280 tokens per second | $0.59/$0.79 |
| Mixtral 8x7B SMoE (32k context length) | ~480 tokens per second | $0.27/$0.27 |
| Llama 3 8B | ~870 tokens per second | $0.05/$0.10 |
| Gemma 7B (8K context length) | ~820 tokens per second | $0.10/$0.10 |
Artificial Analysis measured Groq’s Mixtral 8x7B Instruct API against other cloud-inference providers and found that it offered competitive pricing of $0.27 USD per 1 million tokens while offering significantly higher throughput than competitors such as Perplexity, DeepInfra, Lepton, Anyscale, Together.ai, Fireworks, and Mistral.
430 tokens/s on Mixtral 8x7B: @GroqInc sets new LLM throughput record
Groq has launched its new Mixtral 8x7B Instruct API, delivering record performance on its custom silicon. Pricing is competitive at $0.27 USD per 1M tokens, amongst the lowest prices on offer for Mixtral 8x7B.… pic.twitter.com/8DwYLofIM8
— Artificial Analysis (@ArtificialAnlys) February 14, 2024
This means that Groq requires less overall computing power than other providers that need to consume more resources to process fewer tokens. So, in this instance, Groq is a cheaper option.
Groq Applications
Groq is a good fit for several core use cases. These include:
- High-Speed Inference: Groq’s LPU outperforms CPUs and GPUs in running inference tasks for large language models, ensuring rapid processing.
- Real-time Program Generation and Execution: Leveraging Groq alongside models like Llama 3 facilitates the creation and immediate execution of programs, enabling real-time responsiveness.
- Versatile LLM Support: Groq runs high-performance LLMs such as Llama 3, Mixtral 8x7B, and Gemma, providing a platform for diverse computational needs.
- Scalability for Large Models: Capable of supporting different models, Groq scales to handle both small and large LLMs, including those exceeding 70B parameters.
Groq AI Limitations
While Groq is extremely useful, it has some significant limitations. These are as follows:
- User Experience: While it runs extremely fast, its inference engine’s GUI offers a less polished user experience than other tools like ChatGPT (w/ GPT-4).
- Limited Transparency: There’s limited information available about the capabilities of LPUs.
- Lack of Focus on Training: Inference is only one side of the equation, and many organizations want to optimize both training and inference.
Groq AI Vision & Strategy: Future Plans
One of the biggest challenges that Groq is facing is that it needs to convince enterprises that Groq chips are a better alternative than Nvidia’s, which, according to some estimates, holds 80% to 95% market share in the AI chips market.
Groq appears to be meeting this challenge head on, openly calling out Nvidia’s launch of the Blackwell chips in a blog post and saying:
“NVIDIA’s Blackwell isn’t just faster horses, it’s more of them, tied to more buggies, yoked together by an expanding network of harnesses. The scale is stupendous, the engineering remarkable, and, it’s still a horse and buggy architecture.”
Thus, the strategy is to position LPUs as the successor to GPUs to provide enterprises with greater performance and energy efficiency. Naturally, this includes enhancing the capabilities of the LPU over time.
As one Groq developer on Reddit explained, “It’s safe to assume the next generation will be a step up in performance, power efficiency, and scalability. That necessitates increased memory and assuring interconnectivity between chips is seamless at a larger scale.
“We’re definitely considering the implication that models have been growing in size ~2x a year, and we’re trying to sign hardware that will tackle this and maintain a great user experience.”
The Bottom Line
Groq has rapidly become one of the most exciting providers in the LLM market and is in a solid position to be a key enabler of AI model development in the future.
As it stands, its ability to complete inference tasks at high speeds makes it a great option for those who require high throughput at a low cost.
FAQs
What is Groq LPU?
Is Groq better than Nvidia?
What is Groq used for?
Who is the CEO of Groq?
References
- AI chip company Groq plans fresh funding round (Data Centre Dynamics)
- Now Run Programs in Real Time with Llama 3 on Groq (Analytics India Magazine)
- GPT-4: Quality, Performance & Price Analysis (Artificial Analysis)
- Groq Official Website (Groq)
- Artificial Analysis’ tweet (Twitter)
- Nvidia Sells Graphics and AI Chips, but 15% of Sales Come From Other Multi-Hundred-Billion Dollar Markets (Yahoo Finance)
- What NVIDIA Didn’t Say (Groq)
- New chip technology allows AI to respond in realtime! (GROQ) (Reddit)






















