

















What Is an Adversarial Attack?
An adversarial attack in machine learning (ML) refers to the deliberate creation of inputs to deceive ML models, leading to incorrect predictions or classifications. Also known as adversarial AI, it can be more generally explained as attacks that target vulnerabilities in artificial intelligence (AI) systems both during training and after the model is deployed.
For example, one type of adversarial attack, known as data poisoning, involves adversaries – also called threat actors – altering classification data during the training phase to mislead artificial intelligence algorithms. A variation of this is a backdoor attack, where adversaries insert hidden triggers into the training data causing it to misclassify when the trigger is present.
Another type, called model poisoning, can be introduced post-training, where malicious inputs are designed to deceive the model during operation.
Adversarial attacks are often categorized as white or black-box attacks:
- White-box attack: The adversary has access to the ML model’s architecture and training data.
- Black-box attack: The adversary does not have knowledge of the model – they can only query and analyze the outputs.
What is the purpose of an adversarial attack? In simple terms, the purpose is to exploit vulnerabilities in ML models to manipulate future predictions or to steal models or the data. Like any cyberattack, it’s driven by the attacker’s specific motives. While real-world attacks are typically malicious, many adversarial attacks are the result of research efforts to highlight vulnerabilities in machine learning models and the need for stronger cybersecurity defenses.
The broader study of attacking and defending ML models is known as adversarial machine learning (AML).

Key Takeaways
- An adversarial attack targets vulnerabilities in AI systems both during training and after the model is deployed.
- Adversarial attacks are often categorized as white or black-box attacks.
- Evasion attacks modify inputs to mislead the machine learning model when making predictions.
- The broader study of attacking and defending ML models is known as adversarial machine learning.
- Two in five organizations have experienced an AI privacy breach or security incident.
How Adversarial Attack Works
Machine learning uses large data sets – structured or unstructured collections of data related to a particular subject. An adversarial attack can manipulate this data to deceive the model.
For example, data poisoning introduces mislabeled or malicious data during training. In this case, feeding the model images of dogs labeled as cats could cause the ML model to incorrectly classify dogs in future predictions.
Another form of adversarial attack involves adversarial perturbations – small, crafted changes to input data. These changes are cleverly designed to be imperceptible to humans but intentionally mislead the model. For instance, slight pixel alterations in a photo would likely go unnoticed by the human eye but may cause facial recognition systems to misidentify the person.
If undetected, these attacks can lead to inaccurate predictions or flawed decisions in AI-powered applications that rely on the compromised ML model.
Types of Adversarial Attacks
| Type of adversarial attacks | How it works | Targets |
|---|---|---|
| Evasion attack | Modifies inputs to mislead the model when making predictions on new data (i.e., during inference) | Deployed model |
| Gradient manipulation attack | Alters gradients to mislead model learning | Training process |
| Inference attack | Extracts sensitive information from model outputs | Deployed model |
| Model extraction | Replicates the model through repeated queries | Deployed model |
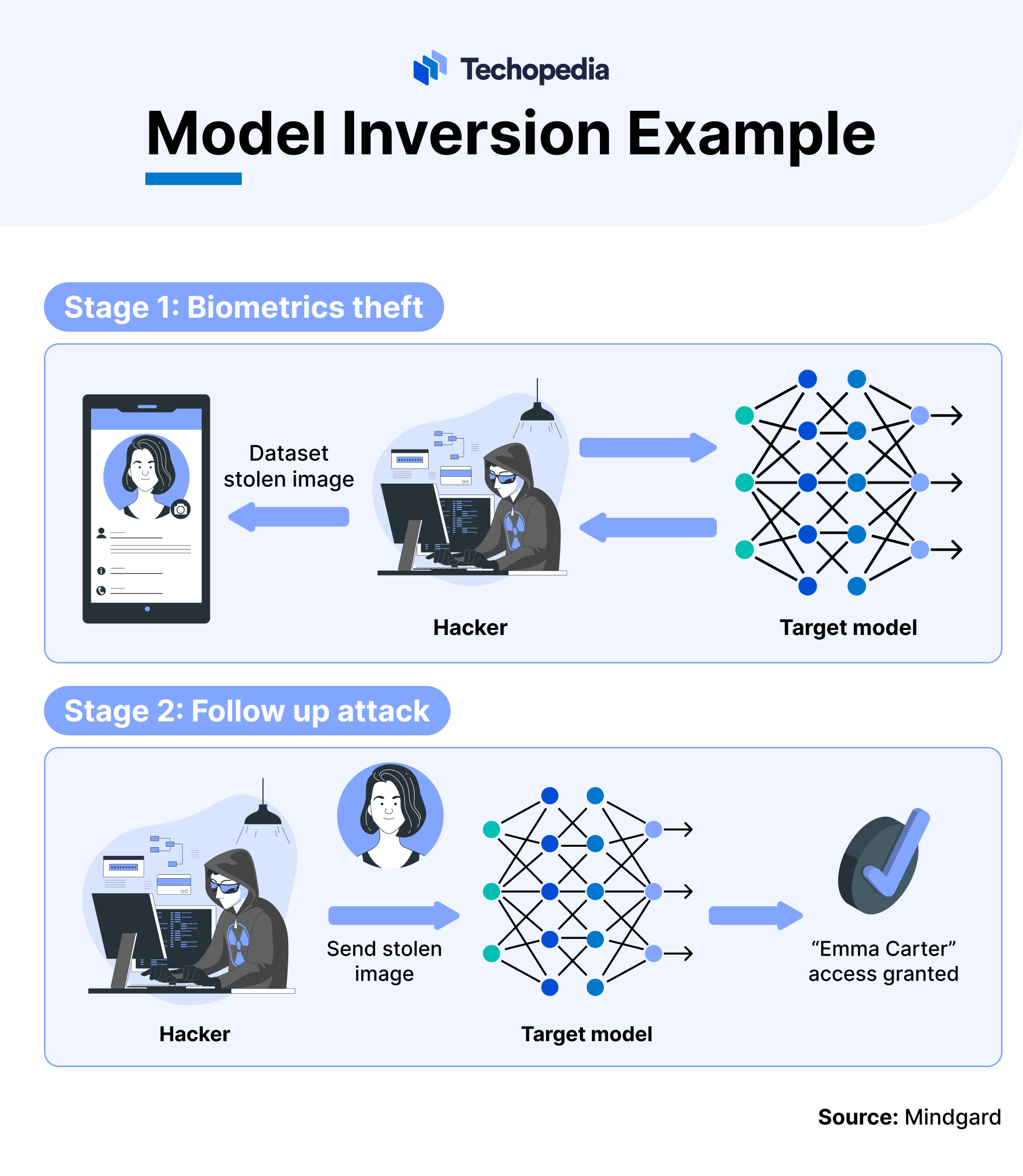
| Model inversion | Reverse-engineers training data from model predictions | Deployed model |
| Poisoning attack | Injects malicious data during training | Training process |
Adversarial Attack Defense Strategies
A recent ISACA report revealed that two in five organizations experienced an AI privacy breach or security incident, with one in four considered malicious. As machine learning advances, adversarial machine learning evolves alongside it, with defense strategies adapting to counter-exploises.
Examples include:
Examples of Adversarial Attacks
In 2016, Microsoft launched Tay, a chatbot designed for entertainment purposes on X (formerly Twitter). In under 24 hours it was shut down after a group of users exploited a vulnerability, flooding it with offensive content. Tay posted tweets with racist, sexist, and anti-Semitic language, prompting Microsoft to take it offline.
A form of adversarial attack in natural language processing (NLP), that involves adversaries targeting AI content generators by crafting inputs that manipulate language models into generating unintended or harmful content. Researcher Michael Bargury demonstrated this by turning Microsoft Copilot into an automated phishing machine.
How to Protect Yourself From Adversarial Attack
To protect yourself and your organization, experts recommend combining proactive and reactive adversarial defense methods with general cybersecurity practices such as risk assessment and mitigation.
- Risk assessment and mitigation: Develop strategies to identify vulnerabilities and reduce exposure to adversarial attacks before deploying models.
- Reactive defenses: Detect and respond to adversarial attacks after they occur (e.g., adversarial example detection, anomaly detection, model monitoring).
- Proactive defenses: Design machine learning models to resist adversarial attacks (e.g., adversarial training, gradient masking, robust optimization).
Adversarial Attack Pros and Cons
Pros
- Can be used to secure models
- Encourages better data practices
- Improves model robustness
Cons
- Computationally intensive
- Limited effectiveness across different attacks
- Time-consuming and often impractical
The Bottom Line
The definition of adversarial attack refers to the deliberate creation of inputs to deceive ML models, exploiting vulnerabilities in AI systems both during training and after deployment. Data poisoning attacks alter classification data during training, while model poisoning is introduced post-training to deceive the model during operation.
As machine learning advances, adversarial machine learning evolves alongside it. Defense strategies, such as adversarial training, data preprocessing, and general cybersecurity practices, can help protect organizations from adversarial attacks. Keep in mind that adversarial techniques can also be used to encourage better data practices and improve model robustness. However, if not secured, machine learning systems can be compromised.




















