
















What is Machine Learning (ML)?
Machine learning (ML) is a subset of artificial intelligence (AI) that uses mathematical algorithms and data to imitate the way humans learn from experience. The objective of machine learning is to make informed decisions or predictions based on past interactions with similar types of data. The goal of machine learning is to make better predictions or decisions as more data becomes available.
One common application of machine learning is seen in generative AI and Large Language Models (LLMs) that are the driving force behind AI content generators and tools like AI content summarizers. LLMs use a type of machine learning called deep learning to train themselves on large data sets to generate natural, human-like language.
Many of the machine learning algorithms in use today are designed to make predictions. They analyze data to identify patterns and correlations, and then use those patterns to forecast future events or estimate unknown values.
More sophisticated machine learning algorithms can make decisions using predictions in conjunction with predefined rules or policies. This type of machine learning algorithm is often used to make recommendations or directly trigger actions.
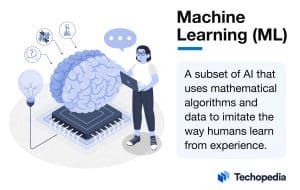
Key Takeaways
- ML is a branch of AI that uses algorithms and data to enable computers to learn from past data and improve predictions.
- ML follows steps like data collection, preparation, training, and evaluation to create models that can predict or make decisions on new data.
- Major ML types include supervised, unsupervised, semi-supervised, reinforcement learning, and deep learning.
- ML is used in healthcare, finance, retail, and transportation, enhancing tasks from fraud detection to personalized recommendations.
- ML requires quality data, is computationally demanding, and can raise ethical concerns if it replicates biases present in the data.
Machine Learning History
In the early 1940s, Warren McCulloch and Walter Pitts co-authored a groundbreaking paper that inspired Alan Turing and other mathematicians to become interested in the potential for artificial intelligence to become more than just a theoretical concept.
Their paper, which was entitled “A Logical Calculus of the Ideas Immanent in Nervous Activity,” introduced the idea that activity in the human brain can be understood in terms of binary logic. This was important because it opened the door to understanding intelligence in algorithmic terms.
In the 1950s, Arthur Samuel’s work introduced the concept that binary logic, like human intelligence, could improve with experience. Around the same time, Frank Rosenblatt introduced the Perceptron, a machine that could learn to recognize simple visual patterns. Samuel’s and Rosenblatt’s work paved the way for the development of more sophisticated algorithms thirty years later.
In 1986, David E. Rumelhart, Geoffrey Hinton, and Ronald J. Williams released a paper entitled “Learning Representations by Back-propagating Errors.” This paper provided clear examples and demonstrated the practical effectiveness of layering algorithms to train neural networks. Their work helped to re-ignite widespread interest in AI and laid the groundwork for what would become known as deep learning.
By the turn of the century, researchers were able to use deep learning to train much larger neural networks, which led to breakthroughs in tasks like image recognition and computer vision. Further advancements were fueled later on by the increasing availability of big data and GPU computing.
How Machine Learning Works
Machine learning uses algorithms to parse data inputs, analyze them, and make predictions or decisions.
Here’s a simplified explanation of how the process typically works:
Data Collection
The process begins by collecting large amounts of data relevant to the task at hand.Data Preparation
The next step is to clean the collected data and split it into a training set and a test set. Robotic process automation (RPA) can be used to automate parts of the data pre-processing workflow.Choosing a Learning Algorithm
There are many different approaches to designing machine learning algorithms, and the choice depends on what type of task the algorithm will be used for.Training the Machine Learning Model
The training process involves running the algorithm on training data until it understands patterns in the data and can make accurate predictions about new data. During the training process, the algorithm uses its own outputs to adjust internal parameters. The final version of the algorithm after training is referred to as the machine learning model.Evaluation
After training, the model is evaluated. This involves using the test set to see how well the ML model performs on unseen data. Metrics like accuracy, precision, and recall can be used to measure performance.Model Fine-Tuning
After the evaluation, the model may need human help to adjust parameters or switch to a different machine learning algorithm.Make Predictions
Once trained and tuned, the model can be used to make predictions or decisions based on new data.
Machine Learning Algorithms
Machine learning algorithms can be broadly classified by the tasks they are designed for and the way they use data to learn how to complete the task.
Here’s an overview of the main types of machine learning algorithms and some notable examples within each category:
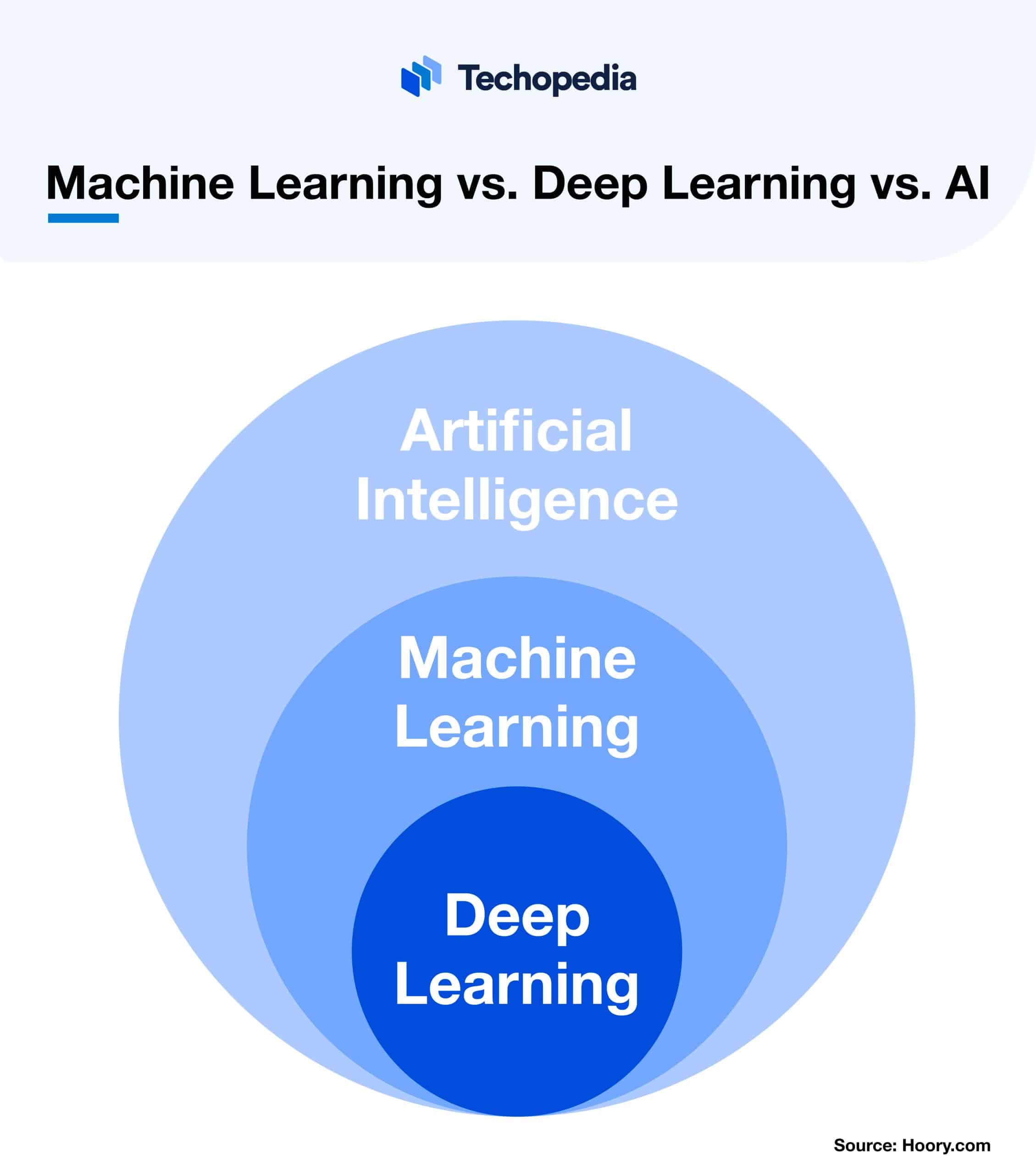
Machine Learning vs. Deep Learning vs. AI
News articles and pop culture often use “AI” as a catch-all term, even when referring to specific types of AI like machine learning or deep learning. Terms like “learning,” “algorithm,” and “data” are used across all three fields, which can make them seem more similar than they are.
To differentiate between them, it can be useful to think about how each of these terms in machine learning’s meaning relates to the other.
Quite simply, deep learning is a specific type of machine learning, and machine learning is a specific type of artificial intelligence.
Machine Learning Types of Deployment
Machine learning can be deployed in-house, in the cloud, and at the edge of a network. Each type of deployment has advantages and challenges, and the choice often depends on the specific needs of the application in terms of speed, cost, security, and regulatory compliance requirements.
Here are some common types of machine learning deployments:
This approach involves deploying machine learning models directly within an organization’s own IT infrastructure. This type of deployment allows an organization to have full control over the hardware and software environment.
Many organizations opt to deploy their machine learning models in the cloud due to the flexibility, scalability, and reduced overhead it offers. Cloud providers like AWS, Google Cloud, and Microsoft Azure can provide powerful platforms that will support the entire machine learning lifecycle, from data preprocessing and model training to deployment and monitoring.
In edge deployments, machine learning models are used on edge devices like smartphones, Internet of things (IoT) network nodes, or local servers. This approach is useful for applications that require real-time processing and need to make decisions without the latency that can come from two-way communication with a central server.
A hybrid approach combines on-premise and cloud deployments. For example, critical data and computations might be handled on-premises for security reasons, while less sensitive tasks are offloaded to the cloud to benefit from its scalability, efficiency, and relatively low cost.
Machine Learning as a Service
Machine learning as a service (MLaaS) is a fast-growing trend in which third-party service providers or managed service providers offer machine learning resources through a subscription or per-per-use pricing model.
This approach allows companies to use machine learning technologies without the need to invest in and maintain the underlying infrastructure or staffing.
MLaaS can be a cost-effective option for organizations that want to experiment with machine learning or implement ML capabilities quickly but lack deep expertise and/or the underlying infrastructure.
What Causes Bias in Machine Learning?
Machine bias is a complex issue that can be influenced by a combination of data-related, algorithmic, and human factors.
When the data used to train a model doesn’t accurately reflect the diversity of the real world, or if it contains historical biases and prejudices, the model will learn those biases and replicate them.
The parameters that a model adjusts autonomously during training can also cause bias. If important features that could influence outputs are omitted, or if irrelevant features are given too much weight, the model’s accuracy and fairness can be compromised.
Human mistakes in the choice of algorithms, their interpretation, and their deployment also play a big role in machine bias. Prioritizing certain metrics over others can influence how a model is tuned and, consequently, how it performs in various groups.
Addressing machine learning bias isn’t simple. It requires attention to the quality and representativeness of data, the development of algorithms that can mitigate bias, transparency tools that can understand the reasoning behind model decisions, and continuous human oversight to identify and fix the bias that the model perpetuates.
Machine Learning Examples and Applications
Machine learning applications are versatile and the technology’s impact can be felt across just about every aspect of today’s workplace in many sectors of the economy.
Machine Learning Pros and Cons
Machine learning offers many advantages, but it also comes with many challenges.
One of the most significant advantages is the technology’s ability to process and analyze vast amounts of data much faster and more efficiently than humans can. This capability allows businesses to gain insights from their proprietary data that were previously impossible or financially impractical to obtain.
Because machine learning systems can learn from new data, they can improve their own performance with minimal human intervention. In addition to facilitating data-driven decision-making, their use will help organizations increase efficiency and employees improve their personal productivity.
It’s important to remember, however, that machine learning also has its drawbacks.
One major concern involves the quantity and quality of the data that’s used to train algorithms. If the training data is biased or incomplete, the model will likely perform poorly or perpetuate existing biases, which can lead to unfair or harmful outcomes.
This is particularly important in machine learning software used in human resource management or law enforcement where biased AI decisions can have serious implications for people’s lives.
Another drawback is that some types of machine learning models, like large language models (LLMs), require a lot of computational power, which can be both costly and environmentally demanding.
The complexity of sophisticated models also makes them difficult to understand and interpret, which can lead to black box models, a condition in which the prediction and/or decision-making process is opaque and not easily explainable. The lack of transparency can be a barrier in sectors where understanding the decision-making process is important for determining legal liability if a machine learning model’s outputs are flawed.
Lastly, and perhaps most importantly, machine learning can raise security risks if the technology is not designed and/or implemented well.
Cyberattacks on training data and machine learning models can be difficult to detect and severely impact outputs. Security management plays an important role in both machine learning development and machine learning operations (MLops).
MLOps
Machine learning operations is an approach to managing machine learning model lifecycle management that is modeled after DevOps, a well-established approach to holistically managing software development cycles.
MLOps best practices are intended to bridge the gap between machine learning development, deployment, and their maintenance in production environments. The goal is to ensure that models avoid model drift and continue to provide accurate predictions, and make useful decisions under changing conditions.
Ideally, MLOps teams consist of data scientists, data engineers, software developers, machine learning engineers, and IT operations management staff.
To be most effective, MLOps teams should also help ensure that the ML models they develop, implement, and support are scalable, reproducible, and transparent.
How to Become a Machine Learning Engineer
Machine learning engineers play an important role in MLOps.
Candidates for high paying machine learning jobs should have a degree in computer science or a related field and a strong background in mathematics and statistics.
This job role typically requires programming skills in languages like Python or R and requires candidates to have working knowledge of TensorFlow and PyTorch.
It’s also important for job candidates to understand all kinds of machine learning algorithms as well as different types of deployment models. Practical experience can be gained through personal projects, internships, or contributions to open source machine learning projects on GitHub.
Machine learning has so many applications in the real world that as ML engineers gain more experience, they often specialize in a niche area of the technology that requires specific skills. Those candidates who are interested in natural language processing (NLP) or computer vision, for example, should have a working knowledge of neural networks and deep learning and consider acquiring certifications for both areas of expertise.
The Bottom Line
Machine learning is a powerful subset of artificial intelligence that uses algorithms to learn from data and make predictions or decisions without being explicitly programmed for every possibility.
Machine learning is increasingly being used to gain insights from big data, automate workflows, and make data-driven decisions in real time. Maintaining machine learning systems in production requires ongoing efforts to ensure model outputs remain accurate, useful, and unbiased as input data and conditions change.
FAQs
What is machine learning in simple terms?
What is the difference between AI and ML?
What are the 4 basics of machine learning?
What is the main purpose of machine learning?
References
- A logical calculus of the ideas immanent in Nervous activity* (Cs.cmu)
- Computer Pioneers – Arthur Lee Samuel (History.computer)
- Professor’s perceptron paved the way for AI – 60 years too soon | Cornell Chronicle (News.cornell)
- Cs.utoronto (Cs.utoronto)
- Microsoft Association Algorithm | Microsoft Learn (Learn.microsoft)
- PyTorch (Pytorch)
- Looking for a Open Source Machine Learning Project · community · Discussion #42677 · GitHub (Github)
- Our Quest to Support Game Developers on Discord (Discord)
- About Discord | Our Mission and Values (Discord)
- Discord to Offer Rewards for Gamers as App Seeks Profit in 2024 – Bloomberg (Bloomberg)
- Discord CEO on audio app’s next big moves with $500 million funding (Cnbc)
- Discord Stock Price, Funding, Valuation, Revenue & Financial Statements (Cbinsights)
- Discord IAP revenues worldwide 2023 | Statista (Statista)
- Complete Your Look in the Shop, Now Open to All (Discord)
- Discord’s store tries to top Steam by offering developers more money – The Verge (Theverge)
- Discord and Spotify – Spotify (Support.spotify)
- How We’re Building the Future of Discord (Discord)
- How Trust & Safety Addresses Violent Extremism on Discord (Discord)
- Discord to Offer Rewards for Gamers as App Seeks Profit in 2024 – Bloomberg (Bloomberg)




















