

















What is Differential Privacy?
Differential privacy is a mathematical framework for determining a quantifiable and adjustable level of privacy protection. The purpose of differential privacy is to reduce the ethical, reputational, and financial risks of sharing or using data that contains sensitive or personally identifiable information (PII) for statistical analysis, data analytics, and machine learning (ML).
Essentially, differential privacy quantifies how difficult it would be for someone to trace an aggregated data instance back to a specific individual.
The framework balances the need for data utility with the need for data privacy and ensures that useful information can be extracted from large datasets without compromising anyone’s privacy.
Techopedia Explains
While traditional methods for anonymizing data can still offer a layer of protection and act as a deterrent for low-level cyberattacks, they are not robust enough to mitigate the risks associated with linkage attacks that use auxiliary information to re-identify individuals.
Differential privacy mitigates risk by ensuring that statistical and algorithmic outputs are not influenced by an individual person’s data in a dataset.
Typically, this involves adding a controlled amount of random noise to the data or the analysis results. In this context, noise is a deliberate change in data or query results that masks the presence or absence of a specific individual’s data in a dataset.
What Does Differential Privacy Do?
The differential privacy framework provides data owners and data holders with a structured way to assess and control acceptable risk while ensuring that aggregated data retains its usefulness for analytics and machine learning decisions.
The framework’s mathematical approach has four important advantages over previous privacy techniques:
- It assumes all information is identifying information. This is a significant shift from traditional approaches that are needed to identify and protect certain data fields.
- It uses a privacy parameter to answer the question “How much privacy is enough?” The parameter allows organizations to guarantee a quantifiable level of privacy and manage privacy loss across multiple queries.
- It is resistant to linkage attacks that allow adversaries to re-identify individuals by correlating anonymized data with other available data.
- In the event of a data breach, the quantifiable random noise introduced through differential privacy can potentially help protect the data holder from legal and ethical ramifications associated with the breach.
How Does Differential Privacy Work?
Differential privacy makes it statistically improbable for an observer to determine whether any specific individual’s data was included in a computation. It ensures that the presence or absence of a single data point won’t significantly affect the outcome of statistical analysis, data analytics, or queries.
The most basic technique involves adding controlled amounts of random noise to either the data or query results. The noise can be added in various ways, depending on the specific differential privacy algorithm that’s been chosen.
The Laplace mechanism is one of the most popular algorithms used to implement differential privacy and add random noise. The level of noise in this mechanism is determined by two things: the privacy parameter that’s selected, and the sensitivity of the query or data operation that’s being performed.
Privacy Parameter
The privacy parameter, which is typically represented by the Greek letter epsilon (ε), quantifies the acceptable level of privacy loss for each query or mathematical operation. This parameter influences the amount of noise that needs to be added to ensure privacy, and each query’s consumption of ε contributes to the total privacy loss budget for the dataset.
The privacy loss budget is the total allowable limit of privacy loss over multiple queries. Each query consumes some of this budget based on its ε value.
The choice of ε is determined by the data holder and involves a trade-off between privacy and data utility. Too much noise can reduce the data’s usefulness, while too little noise can expose the data owner or holder to financial and reputational risk.
Sensitivity
Sensitivity measures the maximum amount a query result would change if a single record in the dataset was either included or excluded.
The change is calculated by determining the largest difference in output for all possible pairs of adjacent datasets.
In cases of high sensitivity, where a single record can significantly alter the outcome, a greater amount of noise is necessary to reduce the influence of any individual record and maintain privacy.
| Term | Description | Role in Differential Privacy |
| Privacy Parameter (ε) | Quantifies the acceptable level of privacy loss (privacy loss budget). | Determines the amount of noise that needs to be added to guarantee a desired privacy level. |
| Sensitivity | Measures the maximum change in a query output if a single individual’s data is added or removed. | Influences the scale of the noise required to guarantee privacy. Scale determines the statistical spread of noise values. |
How to Implement Differential Privacy
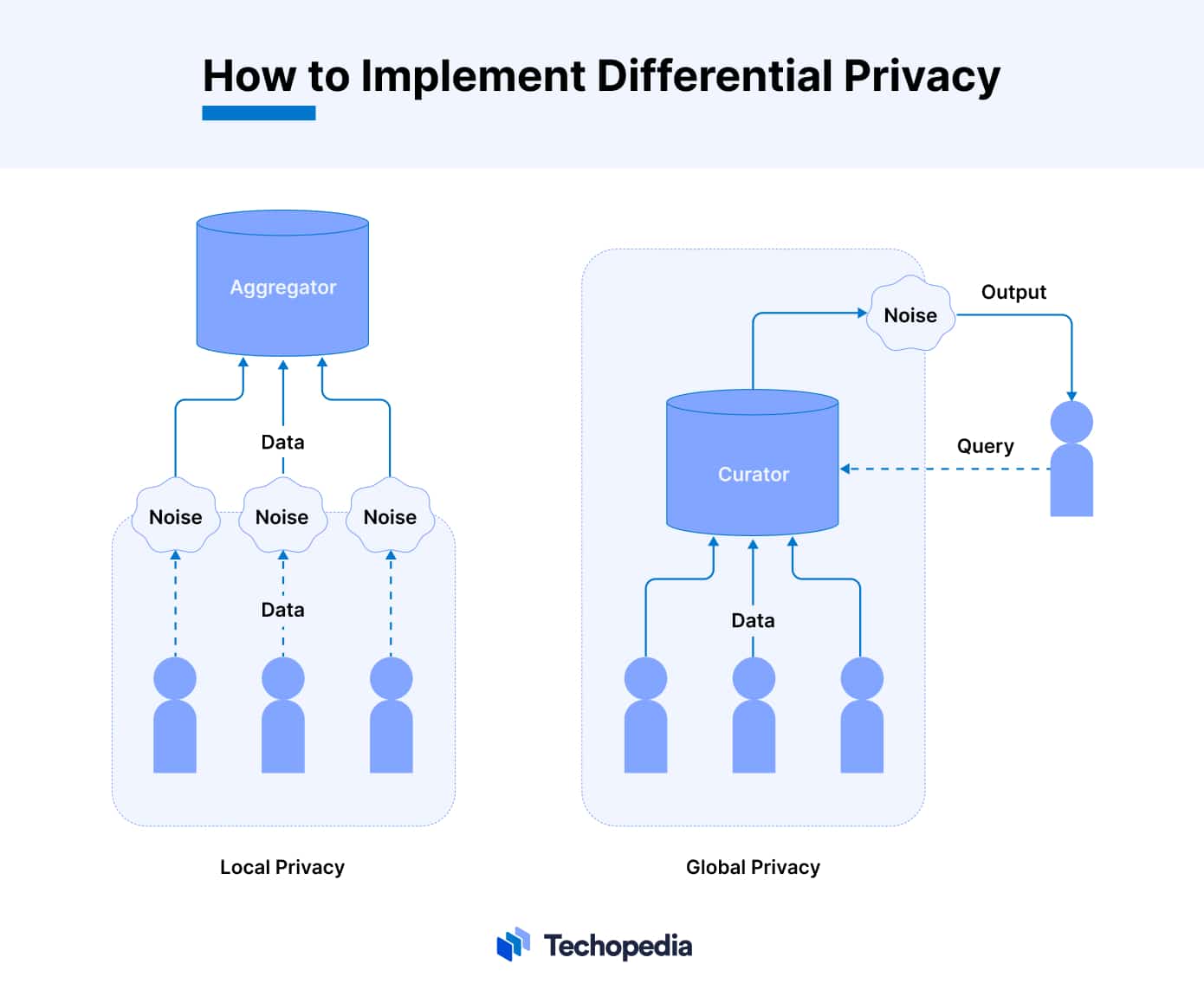
Differential privacy can be implemented locally or globally. Local differential privacy (LDP) requires the data owner to add noise to each data instance before sharing their data. This approach ensures privacy at the point of collection.
In contrast, global differential privacy (GDP) adds noise to the outputs of queries on the data. This approach, which may also be referred to as central differential privacy, leaves the original data untouched.
The choice between LDP and GDP often depends on the specific privacy requirements, the level of trust in the entity that is handling the data, and the need for data accuracy.
What is the Role of Differential Privacy in Machine Learning?
Differential privacy allows machine learning algorithms to identify patterns and learn from data without compromising the specific details of individual data points.
In theory, this means that when a differentially private machine learning model is trained, it becomes difficult (if not impossible) for attackers to reverse engineer the model and try to locate personal information in training data.
This is important because an increasing number of data privacy laws and regulations require organizations to ensure that personal data is not misused or disclosed without consent. Differential privacy helps organizations use sensitive data for analytical and predictive purposes, and still stay in compliance with regulatory mandates.
Examples of Companies and Market Segments That Use Differential Privacy
Large tech companies like Apple, Google, and Microsoft are using differential privacy to protect end-user data when they collect information for product improvement and personalized services.
Governmental agencies are also using differential privacy to protect people’s privacy when they publish statistical data. For example, the U.S. Census Bureau has started to use differential privacy to protect sensitive information in census data.
Other examples of differential privacy use cases today include:
- Research Institutions: Academic researchers and institutions use differential privacy to analyze sensitive datasets in fields like healthcare, social science, and economics while maintaining the confidentiality of individual participants.
- Healthcare Sector: Hospitals and health research organizations apply differential privacy to share and analyze medical data, ensuring patient privacy and complying with regulations like the HIPAA Privacy Rule.
- Financial Institutions: Banks and financial companies use differential privacy for analyzing transaction data and customer credit risk without revealing individual client information.
- Social Media Platforms: Some social media companies like Facebook and Snapchat use differential privacy to analyze user data for trends and insights while preserving the privacy of individual users.
- Data Analytics and Market Research Firms: These firms use differential privacy to analyze consumer behavior and market trends without compromising the privacy of the individuals in their datasets.
FAQs
What is differential privacy in a nutshell?
What is an example of a differential privacy algorithm?
Who uses differential privacy?
What is differential privacy on an iPhone?
References
- Protecting Against Linkage Attacks that Use ‘Anonymous Data‘ (MarkLogic)
- Laplace Mechanism (Gautamkamath)
- Ted is writing things (Desfontain)
- Differential Privacy (Apple)
- How we’re helping developers with differential privacy (Google for developers)
- Putting differential privacy into practice to use data responsibly (Microsoft)
- Census (Census)
- Differential Privacy for Credit Risk Model (Cornell university)
- New privacy-protected Facebook data for independent research on social media’s impact on democracy (Facebook)
- Differential Privacy at Snapchat (Snap)
- Recap of Laplace Mechanism (UPenn Cis)
- Apple’s ‘Differential Privacy’ Is About Collecting Your Data—But Not Your Data (Wired)











![Inside the Scottish Government’s Tech Transformation: Interview with Neill Smith [Exclusive]](https://www.techopedia.com/wp-content/uploads/2023/11/gears_03-300x150.jpg)








