

















What is Stable Diffusion?
Stable Diffusion is an open-source generative AI model that uses text prompts to generate new images or alter existing images.
Technically, Stable Diffusion is a latent diffusion model (LDM) for machine learning. This type of specialized deep learning model uses probability distributions to generate outputs that are statistically similar to the data the model was trained on.
In addition to generating new images, Stable Diffusion can also be used for inpainting or outpainting elements within an existing image, as well as image-to-image translation.
- Inpainting is the process of filling in missing or corrupted parts of an image. It is a common task in image restoration and editing and can be used to remove objects from images, repair damaged photos, or complete incomplete images.
- Outpainting is the process of extending an image beyond its original borders. It can be used to create larger images, add new elements to an image, or change the aspect ratio of an image.
- Image-to-image translation is the process of mapping an input image to an output image. It can be used to change the artistic style of an image, change the appearance of an object in an image, or improve the quality of an image by increasing contrast or color density.
How Does Stable Diffusion Work?
Stable Diffusion was initially trained on human-labeled images scraped from the Internet. The model learned how to improve its outputs by using a technique called reinforcement learning with human feedback (RLHF).
During the initial training phase, the foundation model was tasked with analyzing the probability distribution of latent variables in labeled training data. The latent variables capture the underlying structure and details of a training image and allow the model to learn how likely a specific image will match the text label created by a human.
Stable Diffusion works by applying a diffusion filter to an image of random pixels that averages the values of neighboring pixels. During each iteration of the deep learning process, the filter removes more noise from the image until the remaining pixels statistically match the provided text description.
The latest version of the foundation model, SDXL 1.0, was released in August 2023. It is said to have been trained with 3.5 billion parameters and thousands of hyperparameters. According to the Stability AI website, the reason the model works so well is because it was tested at scale before the release with over 10,000 beta testers who created an average of 1.7 million images a day.
Here is an example of a Stable Diffusion image created with the text prompt “Grey squirrel sniffing yellow flower.”

Here is an example of a Stable Diffusion image created with the text prompt “Origami grey squirrel sniffing a yellow flower.”

Stable Diffusion vs. DALL-E, Midjourney
Stable Diffusion is often compared to DALL-E, a proprietary generative AI image app developed by Open AI, the creator of ChatGPT.
While both AI models were trained on massive amounts of image data, and both are capable of generating useful images, DALL-E is a conditioned diffusion model that uses external information to guide the image generation process. The user’s prompts provide the model with specific guidance for what the generated image should resemble or incorporate.
In contrast, Stable Diffusion is an open-source latent diffusion model that uses text or image prompts to encode a latent representation of the desired image. The latent representation guides the diffusion process to ensure the generated image is statistically similar to the user’s prompt.
Midjourney is a proprietary latent diffusion model for generating images. It is only available through a paid subscription. There are no free or freemium versions available for personal use.
History
Stable Diffusion was first released in 2022 and is funded by a relatively new research and development (R&D) company called Stability AI.
The company’s partnership with Amazon Web Services (AWS) gave developers access to the Ezra-1 UltraCluster supercomputer and supplied Stability AI with the processing power the startup needed to develop complex artificial intelligence (AI) models for image, music, and code generation.
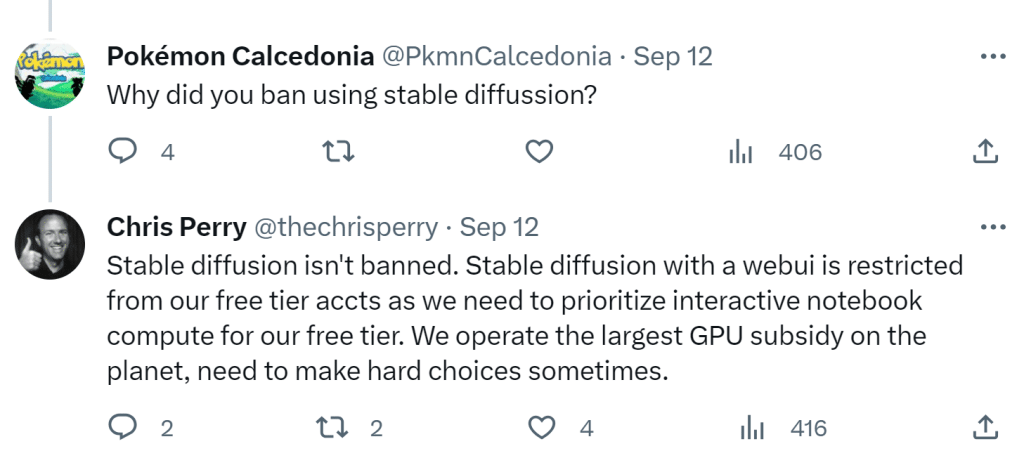
Stability AI’s stated mission is to “make AI more accessible and inclusive.” In September 2023, however, some media outlets reported that users were being banned from running Stable Diffusion on the Google Cloud Platform (GCP).
Chris Perry, a group product manager at Google, responded by tweeting that the company did not ban the generative AI app, but they did put restrictions on free accounts because Stable Diffusion had become so popular. Stability AI founder Mohammad Emad Mostaque tweeted he felt this decision was fair.
How to Use Stable Diffusion
Stable Diffusion can be accessed and tried out for free by visiting the Stability AI website or using DreamStudio or Clipdrop. DreamStudio is Stability AI’s web application for generating and editing images, and Clipdrop is its ecosystem of generative apps, plugins & resources.
The model is also available on a freemium basis from a large number of third-party websites that use Stable Diffusion’s application programming interface (API).
To use Stable Diffusion, follow these steps:
- Open the Stable Diffusion user interface.
- Enter a text prompt that describes an image – or upload an image and enter a text prompt for how the image should be altered.
- Click the Generate button to generate a small number of images based on the text prompt.
- If desired, adjust the text prompts and the model’s latent variables to control various aspects of the output, such as style, content, or theme.
- Once the model generates a desired outcome, save it locally for future use.
3 Tips for Using Stable Diffusion
- Be specific when creating text prompts. This is arguably the most difficult aspect of using Stable Diffusion. The more specific the text prompt, the better the output will be. If the model’s initial outputs are sub-optimal, consider starting the process again with more specific prompts.
- Use negative prompts to exclude specific elements from the model’s output. For example, to generate an image of a cowboy without a hat, use the negative prompt “no hat.”
- If the model is being run locally, consider fine-tuning it with a smaller dataset to meet specific creative needs.
Running Stable Diffusion Locally
To avoid having to pay for using Stable Diffusion at scale, tech-savvy users who agree to Stability AI’s acceptable use policy (AUP) can install the LDM model locally on commodity desktop computers that have a graphics card with at least 7GB of video random access memory (VRAM).
In the near future, Stability AI expects to release optimized versions of their LDM model that will improve both model performance and output quality. They are also planning releases that will allow Stable Diffusion to work on AMD, Macbook M1/M2, and other chipsets. (Currently, NVIDIA chips are recommended.)
Running Stable Diffusion locally is a good option for users who want to generate free images at scale, generate images offline, keep images private, or fine-tune Stable Diffusion outputs to meet a specific use case.
For example, a developer might run Stable Diffusion locally to generate textures and images for a game they are developing.
How to Install Stable Diffusion
After the user has visited the Stability.ai website and verified their computer meets the latest minimum requirements, they will need to download and install both Python and Git. They will also need to create a free account at Hugging Face to get the model weights and then follow these steps:
Step 1: To obtain the Stable Diffusion project files, visit the GitHub page for this project. In the upper right-hand corner, find and click the green “Code” button. From the dropdown menu, select “Download ZIP.” After downloading, extract the ZIP file contents. This action will create a folder named “stable-diffusion-webui-master.” To simplify the installation, copy the entire folder (along with all the extracted files) to the root directory of the host computer’s C: drive.
Step 2: Visit the Hugging Face website and search or browse for the download link for the “768-v-ema.ckpt” file. This file is quite large, so expect a lot of wait time during the download. After the download completes, navigate to this location: “C:\stable-diffusion-webui-master\models\Stable-diffusion.” Within this folder, find a file named “Put Stable Diffusion checkpoints here.txt” and insert the “768-v-ema.ckpt” file.
Step 3: Locate the config YAML file in the downloaded ZIP file from GitHub. Navigate to the “C:\stable-diffusion-webui-master\models\Stable-diffusion” folder and save the YAML file there. Change the file name to “768-v-ema.yaml” while retaining the “.yaml” extension.
Step 4: Move to the “stable-diffusion-webui-master” folder and run the “webui-user.bat” file. Wait for a few minutes. The command window should eventually exhibit a message that reads: “Running on local URL,” followed by a URL containing the IP address of the local machine and a port number. Copy and paste the entire URL (including the port number) into a web browser. This action will open the Stable Diffusion application.
Step 5: Enter a description for the desired image when prompted. Optionally, specify any text to exclude in the Negative prompt box. Adjust parameters, modify the batch count and size as desired, and click the “Generate” button. The application will then display the requested number of images based on the input provided.
Licensing
Stable Diffusion is licensed under the CreativeML Open RAIL-M license, which allows for both commercial and non-commercial use of the model and its outputs.
It is important to note that the license does not cover the copyright for any underlying materials that may be used to generate images with Stable Diffusion.
This means that if a copyrighted photograph is altered by adding or replacing elements within the image (inpainted), extended to make the image bigger (outpainted), or made to resemble a Van Gogh painting (image-to-image translation), the copyright for the newly generated image still belongs to the copyright holder of the original photograph.




















