In today’s digital age, intellectual property theft in the realm of artificial intelligence (AI) is a growing concern, with the overlap of AI and intellectual property rights sparking significant discussion.
As AI systems advance — and there are a growing number of them — they can produce content resembling human creativity, leading to questions about copyright, with many recent controversies highlighting the challenges and solutions faced by industry leaders and legal professionals.
The Zoom Controversy and Beyond
Last week, Zoom faced scrutiny for a change in its Terms of Services (TOS) made in March. The change went largely unnoticed… until someone highlighted the policy shift in a post that quickly gained attention on Hacker News.
Zoom’s alteration granted it exclusive rights to use user data for training future AI modules. Specifically, Zoom claimed a “perpetual, worldwide, non-exclusive, royalty-free, sublicensable, and transferable license” over users’ data. Many believed this included video calls and user messages, leading to negative reactions online.
After the backlash, Zoom clarified its position in a blog post, assuring users it wasn’t using videoconferencing data for AI training. It updated its TOS to reflect this.
Zoom does not use any of your audio, video, chat, screen sharing, attachments or other communications-like Customer Content (such as poll results, whiteboard and reactions) to train Zoom or third-party artificial intelligence models.
This commitment is in its terms of service, in Section 10.
Zoom also pointed out that account owners and administrators have control over enabling its two AI features. These features, Zoom IQ Meeting Summary and Zoom IQ Team Chat Compose enhance the Zoom experience by offering automated meeting summaries and AI-powered chat compositions.
Zoom also ensures participants know via the user interface when these AI services are active.
The Growing Problem of Generative AI and Intellectual Property Theft
As outlined by the Zoom controversy, the swift progression of AI marks a new technological age. Yet, these advancements bring notable challenges, especially concerning intellectual property.
AI models are evolving, and as they become common, distinguishing innovation from infringement gets tricky.
Intellectual Property Theft: Silverman, Golden, Kadrey vs. OpenAI & Meta’s Models
A recent lawsuit by U.S. author Sarah Silverman against OpenAI and Meta highlights this dilemma. Silverman and authors Christopher Golden and Richard Kadrey allege intellectual property theft, claiming that their copyrighted works were used to train AI models without consent.
ChatGPT by OpenAI and LLaMA by Meta are central to this lawsuit. These large language models (LLMs), trained on vast Internet datasets, reportedly used copyrighted materials without permission, such as Silverman’s “The Bedwetter”, Golden’s “Ararat”, and Kadrey’s “Sandman Slim.”
The claimants called the alleged infringement, or specifically the tools that used them, “industrial-strength plagiarists that violate the rights of book authors.”
“Shadow library” sites add complexity to the matter. These platforms provide many copyrighted books and content, perhaps hidden behind a paywall or other barriers to entry – with the lawsuits describing them as “flagrantly illegal.” The suits allege that the authors’ materials were obtained via these shadow libraries to train the models in question.
The concerns aren’t limited to a few authors. Legal representatives Joseph Saveri and Matthew Butterick report widespread concerns, with many writers and publishers expressing concerns over AI tools’ striking capabilities to produce text resembling copyrighted materials, encompassing thousands of books.
Intellectual Property Theft: Andersen, McKernan, Ortiz vs. Stability AI, DeviantArt & Midjourney
In January 2023, the same legal representatives filed the class-action lawsuit against Stability AI, DeviantArt, and Midjourney on behalf of Sarah Andersen, Kelly McKernan, and Karla Ortiz. The lawsuit protests the use of Stable Diffusion, a 21st-century collage tool that remixes the copyrighted works of millions of artists whose work was used as training data.
During a San Francisco hearing on 19 July, U.S. District Judge William Orrick indicated his leaning towards dismissing a majority of the lawsuit. However, he mentioned they could submit a revised complaint.
Orrick emphasized that the artists need to clarify and distinguish their allegations against Stability AI, Midjourney, and DeviantArt. He also noted that they should present more detailed evidence regarding the purported copyright violations, especially since they can access Stability’s pertinent source code.
“Otherwise, it seems implausible that their works are involved,” Orrick said. He noted that the systems have been trained on “five billion compressed images.”
The issue lies in the “substantial similarity” between original works and AI outputs, as traditional copyright claims require a direct comparison between the original and the apparently infringing work. This becomes unclear with AI content.
Ultimately, the legal arena faces challenges due to AI’s swift growth. Notable lawsuits, like those by Sarah Silverman and other artists, reveal shortcomings in current copyright laws. These laws, crafted before AI’s rise, now confront new AI-related issues. As these situations progress, they highlight the urgent need for laws that tackle intellectual property theft in today’s AI-driven world.
Public Opinion on AI Art and Intellectual Property Theft
Outside the courtroom, AI’s swift growth has sparked broad discussions among the public. As AI starts to create art, music, and more, questions about copyright and originality arise. A recent survey by The Verge sheds light on public views about AI art, highlighting concerns about copyright issues and intellectual property theft.
Intellectual Property Theft: The Ethical Dilemma
AI image generators are at the center of intellectual property theft discussions. These tools use large datasets, often from the web, without the original creators’ explicit consent.
 Source: The Verge
Source: The Verge
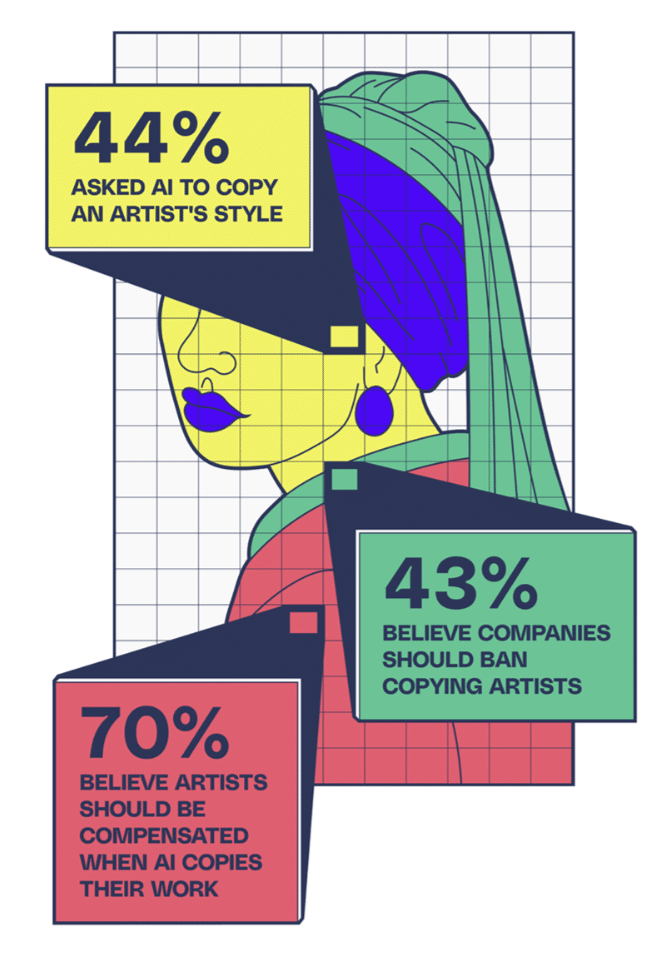
The survey shows public opinion is split on these ethical issues. Notably, 70% think artists deserve compensation if an AI mimics their style. Yet, 43% believe companies should stop AI from making derivative pieces.
Meanwhile, 44% confess to using AI to mimic a familiar artist or writer’s style or voice.
The Call for Better AI Standards
Public sentiment clearly favors stricter standards and regulations for AI, with a significant 78% of survey participants feeling that AI-created digital content should carry a disclosure.
Additionally, 76% think there should be laws governing AI development. They believe AI models should train on verified datasets. Equally, 76% say creating video and audio deep fakes imitating real individuals without their approval should be illegal.
AI’s Societal Impact: Mixed Emotions
The survey reveals mixed feelings about AI’s potential effects on society.
Source: The Verge
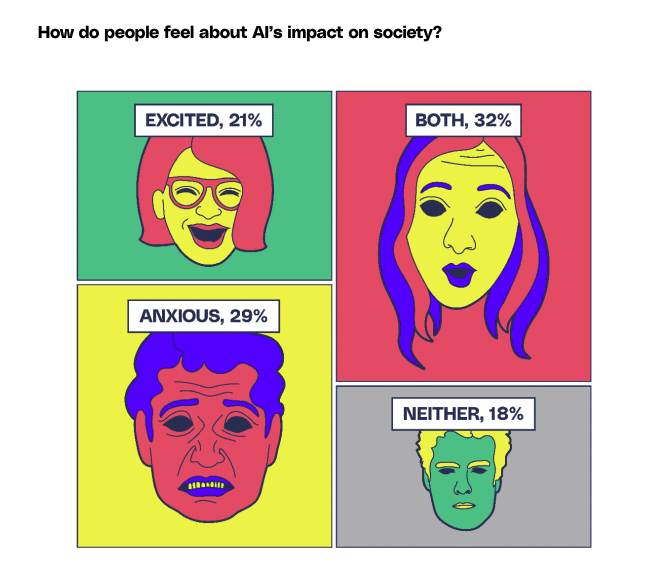
While job loss concerns stand at 63%, threats to privacy are at 68%, and fears of misuse by governments and corporations reach 67%. On the brighter side, there’s optimism for breakthroughs like new medical treatments (51%) and avenues for economic growth (51%).
On the topic of AI’s societal influence, participants showed a near-even split between apprehension and enthusiasm, with many experiencing both emotions.
In conclusion, society faces intricate ethical questions as AI continues to blur the lines between human creativity and machine-generated content. The urgency for robust regulations and a comprehensive grasp of AI’s potential and risks has never been higher.
Mitigating Copyright Issues in AI
As has been highlighted so far, the rapid ascent of AI has amplified concerns about copyright violations. With AI models training on vast internet data, the risk of inadvertently using copyrighted content without proper authorization increases.
Yet, many companies are taking steps to address these issues. They aim to ensure that AI-generated content adheres to intellectual property rights and reduces the risk of intellectual property theft.
Adobe’s Firefly: A Step in the Right Direction
Adobe, a top name in digital media solutions, recently launched Firefly, an AI-driven image-generation tool. Firefly stands out due to its data training approach. Instead of pulling data broadly from the web, Adobe ensures Firefly’s training data is clear of copyright issues by using a dataset of Adobe Stock, along with openly licensed work and public domain content where copyright has expired. This method greatly cuts down the chances of intellectual property theft.
Additionally, aware of the legal challenges tied to AI-created content, Adobe offers another layer of protection for its enterprise clients. It provides indemnification, which is a promise to bear the cost of certain potential lawsuits or claims against their customers. This step not only shows Adobe’s trust in Firefly but also boosts security for businesses using the tool.
Nvidia Picasso: Partnering for Licensed Data
Nvidia, renowned for its strides in AI and graphics, unveiled Picasso, a platform tailored for generative AI visual design. Picasso offers a dynamic framework for creating, tailoring, and rolling out AI models for diverse visual design tasks, spanning image, video, and 3D content.
To champion data integrity, Nvidia has forged key partnerships with Adobe, Getty Images, and Shutterstock. These alliances aim to train Picasso’s AI models using only licensed data. For example, Nvidia and Shutterstock are collaborating to craft models that produce 3D assets from licensed materials.
Such partnerships underscore the need for licensed data in model training, safeguarding against intellectual property theft, and upholding copyright norms.
Copyleaks: Detecting Unlicensed Content in AI-Generated Text
In text generation, Copyleaks presents a tool to spot unlicensed content from AI outputs. This platform aims to monitor generative AI use and pinpoint copyright risks.
Using a cloud-based structure, Copyleaks ensures top-tier security through robust encryption. Given today’s AI scene, where expansive language models, such as ChatGPT, might produce text mirroring copyrighted content, tools like Copyleaks become vital.
They help businesses confirm their AI-generated content steers clear of copyright issues.
The Bottom Line
The rapid evolution of AI technologies brings opportunities and hurdles, especially concerning intellectual property theft, and legislation built for humans copying humans will need to adapt to this new world.
Moving ahead, a balanced strategy promoting innovation and safeguarding intellectual property rights will be vital for the seamless blend of AI and human creativity.