
















What is Web Scraping?
The definition of web scraping is the process of automatically extracting data from a web page. A web scraper extracts a page’s HTML code, plus the data stored in its underlying database, and exports it to a third party.
Legitimate companies may use web scraping to crawl and index websites for search engines and SEO purposes, to collect data for market research, or even to train machine learning (ML) models.
It’s worth noting that web scraping can be done manually or automatically with software. It can also be referred to as web harvesting or content scraping.
Key Takeaways
- Web scraping can be used to extract data from a web page.
- Users can conduct web scraping manually or automatically.
- One of the most well-known examples is the Google bot.
- Using web scraping is generally legal.
- There are some ways you can protect your website against web scrapers.
How Web Scraping Works
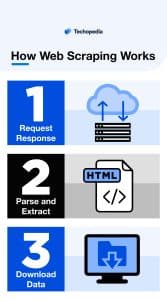
In order to scrape a website, you need to provide a scraper with a URL or series of URLs.
The scraper will then request the website’s HTML file and begin to extract data from the site, outputting structured data into a database, spreadsheet or JavaScript Object Notation (JSON) file. The user can then view the output in a format that’s easy to read.
How Does Automated Web Scraping Work?
Automated web scraping is where you automatically extract data from a website. You can then configure a schedule for data to be scraped from the website.
A good automated scraper can recognise the HTML structure of a website, extract and transform the desired content (even if it’s stored in an API), and store the scraped date, much more efficiently than a manual one.
What is Malicious Web Scraping?
Malicious web scraping is any type of scraping where data is harvested from a website without the permission of the owner.
One of the most common ways this takes place is via content aggregation, where a website invests in producing content, which an unauthorized third party then scrapes and distributes on its own site to steal traffic.
Another type of malicious scraping is where a threat actor scrapes content from a site in an attempt to gather personal information, which they can use to help enable phishing and social engineering scams or sell on the dark web for profit.
Types of Web Scrapers
There are many different types of web scrapers and ways that you can categorize them.
Some of the most basic types are as follows:
Web Scraping Tools
When it comes to prebuilt web scraping tools, there are plenty of options to choose from.
Some of these are as follows:
- ParseHub Office
- ScrapingBee
- Beautiful Soup
- Scrapy
- ProWebScraper
- Mozenda Inc
- Octoparse
- Apify
- Bright Data
Web Scraping Use Cases
Although web scraping can be controversial, there are some legitimate use cases for it.
Some of these are as follows:
Is Web Scraping Legal?
Web scraping is legal so long as it doesn’t infringe on a website’s intellectual property or privacy rights. In one of the most famous cases on the topic, LinkedIn failed to stop a company from scraping personal information from user’s public profiles after a US appeals court upheld the legality of web scraping as a practice.
That being said, this doesn’t mean that web scraping is 100% safe, either. For instance, OpenAI has faced a lawsuit for allegedly training its AI models on content taken from The New York Times and other publications.
6 Ways to Prevent Your Website’s Content From Being Scraped
If you want to prevent your website’s content from being scraped, there are a number of basic steps you can take:
- Use the robots.txt file to decide what pages can be scraped.
- Add a CAPTCHA form to your website to block bots.
- Add an IP block to stop bot access.
- Limit the number of requests visitors can make to prevent performance degradation.
- Use a content delivery network (CDN) to block crawlers.
- Monitor website traffic for bots.
Web Scraping Pros and Cons
Using web scraping comes with a number of pros and cons.
Pros
- Cost-effective technique for collecting data from third-party sites
- Collect highly accurate data from other sites
- Automate the data collection process
- Compile structured data
Cons
- Requires technical expertise to scrape websites
- Measures like IP blocking are designed to thwart web scrapers
- Can create legal liabilities
- Ethical concerns to consider (i.e., has the site consented to have its IP scraped?)
The Bottom Line
Now you know the meaning of web scraping, it’s important to note that the practice is here to stay. While it can be frustrating for content creators, sites can and will get scraped for content. Until the law changes it is the price of owning a website online.
FAQs
What is Web Scraping in simple terms?
What is web scraping in Python?
What is web scraping used for?
What is an example of web scraping?
Do hackers use web scraping?
Can web scraping harm a website?
References
- ParseHub | Free web scraping – The most powerful web scraper
(Parsehub) - ScrapingBee, the best web scraping API. (Scrapingbee)
- ProWebScraper – Fast and Powerful Web Scraping Tool (Prowebscraper)
- Web scraping is legal, US appeals court reaffirms | TechCrunch (Techcrunch)











![Inside the Scottish Government’s Tech Transformation: Interview with Neill Smith [Exclusive]](https://www.techopedia.com/wp-content/uploads/2023/11/gears_03-300x150.jpg)








