















Apple has open-sourced a new multimodal generative AI model called Ferret. Developed jointly by Apple and Cornell University researchers, Ferret was released on GitHub in October 2023 alongside a research paper.
Ferret combines computer vision and natural language processing to take a novel approach to interacting with visual content. It can identify objects and regions within an image, ground textual concepts to visual elements, and leverage this understanding to have nuanced textual conversations about images.
Apple’s Internal Conversational AI Efforts and Investments
Apple’s pursuit of advancements in conversational AI is being led by AI chief John Giannandrea. Giannandrea oversees Apple’s efforts on large language models and reports directly to CEO Tim Cook. He established a dedicated conversational AI team four years ago, with work accelerating since then.
Internally, Apple has a chatbot that some engineers have nicknamed “Apple GPT.” However, the company would likely not use this name publicly for any consumer product. Access to the chatbot is tightly restricted within Apple currently. Its outputs cannot be leveraged for developing new customer product features yet. The chatbot is primarily utilized for internal prototyping and answering queries based on its training data.
Fueling its conversational AI research requires massive investments by Apple for the necessary hardware infrastructure. Training performant large language models demands ample computational resources. As per an analyst, Apple is projected to spend over $4 billion on AI servers in 2024 as it intensifies efforts in this space.
How Ferret Works
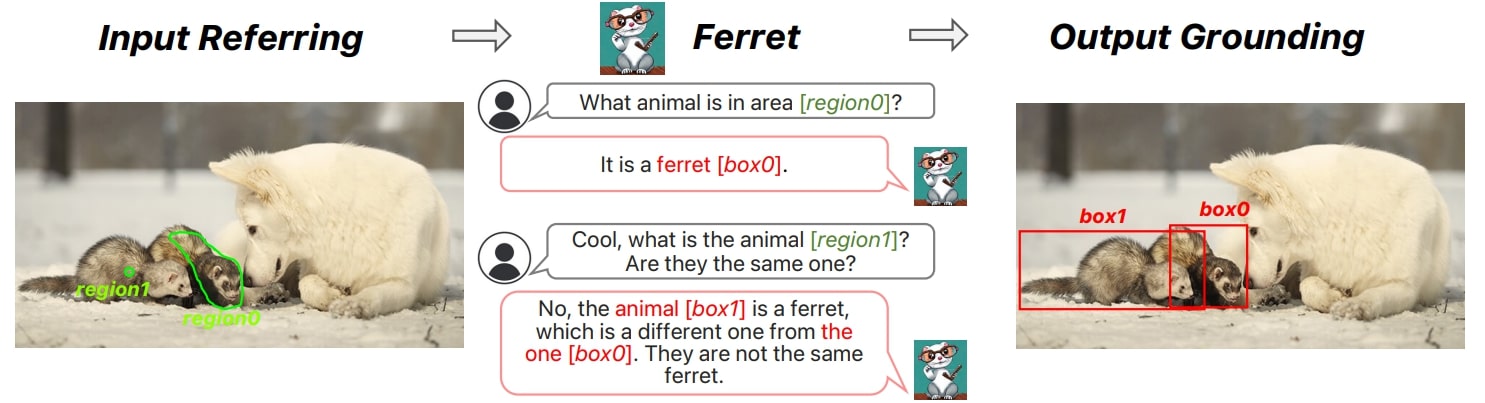
The key innovation of Ferret is its ability to detect semantic objects and concepts within user-specified regions of an image rather than just analyzing the whole image.
For example, a user can draw an irregular shape around a person’s face in a photo and ask “What color are this person’s eyes?” Ferret will then identify the eyes within that region, detect they are blue, and respond, “This person has blue eyes.”
Ferret goes beyond basic object recognition. It can understand relationships between objects, actions, and other contextual details to have a rich, multi-turn conversation about an image. This makes it more capable of region-focused chatting than previous multimodal AI systems.
To achieve this, Ferret leverages a dual-encoder architecture. One encoder focuses on the visual aspects, while the other handles the textual input. The two streams of data are fused using a novel Dynamic Fusion Mechanism. This enables balanced usage of both modalities during training.
Training with Diverse Spatial Data and Reducing Hallucination
To optimize Ferret’s visual referring and grounding capabilities, the researchers carefully curated a large-scale dataset called GRIT (Ground-and-Refer Instruction Tuning). As noted in the paper, GRIT contains over 1.1 million diverse samples with rich spatial knowledge at multiple levels – spanning objects, relationships, region descriptions, and reasoning.
The dataset includes both text-in-location-out and location-in-text-out examples to cover referring and grounding tasks. 34,000 refer-and-ground conversations were generated using models like GPT-3 to make the dataset more instruction-following. Furthermore, 95,000 challenging negative samples were added to improve robustness.
The paper states that when trained on GRIT, Ferret achieved superior performance on conventional referring and grounding benchmarks. More importantly, it significantly outperformed previous multimodal LLMs on tasks requiring region-based understanding and localization during conversational chatting.
According to the researchers, quantitative and qualitative evaluations showed Ferret’s capabilities went beyond existing models. It demonstrated improved fine-grained image description abilities and reduced object hallucination issues prevalent in other LLMs.
The Benefits of Ferret’s Open-Source Approach
Ferret is licensed under a non-commercial open-source license by Apple. This contrasts with the company’s historically closed-off approach to AI research.
Releasing Ferret as open-source brings several advantages:
- Allows wide collaboration: Researchers from all over can build on Ferret’s foundations, and Apple benefits from that collective progress.
- Fosters innovation: With the code publicly available, novel extensions and applications of Ferret can emerge beyond what Apple envisioned.
- Promotes transparency: Open-sourcing assuages concerns about bias and safety that surround closed proprietary AI systems.
The Road Ahead for Ferret
Ferret provides a strong foundation Apple can build on as it pursues advancements in conversational AI. Its open-source release enables collaboration from a wider community of contributors compared to in-house-only development.
Some future directions for Ferret include extending it to other modalities beyond images and text, enhancing its common sense reasoning, and improving its factual grounding. On the application side, Ferret could be incorporated into Apple products like Spotlight visual search to understand user queries about images.
While still an early research project, Ferret lays the groundwork for increasingly capable multimodal systems. It represents an important step forward for AI that can hold genuine visual dialogs. Apple’s move to open-source Ferret means these advancements will come faster through a collaborative community effort.
References
- Apple/ML-Ferret (GitHub)
- Ferret: Refer and Ground Anything Anywhere at Any Granularity (arXiv)
- Apple Boosts Spending to Develop Conversational AI (The Information)
- How much does Apple need to invest annually in generative AI to catch up with the competition? A reasonable estimate starts at several billion US dollars (Medium)




















