

















What is Supervised Learning?
Supervised learning is a type of machine learning (ML) that uses labeled data sets to train predictive artificial intelligence (AI) models. The goal is for the models to learn how to create accurate outputs for new, unseen inputs based on the patterns and relationships found in the training data.

Key Takeaways
- Supervised learning algorithms are good at tasks that involve classification and regression.
- They are trained with labeled data sets that have pairs of corresponding input-output data.
- This type of learning algorithm analyzes the input-output pairs to create a mapping function that relates inputs to outputs.
- The mapping function enables the model to accurately predict outputs for new, unseen inputs.
- Supervised learning outputs are fairly easy to evaluate because the model’s predictions can be directly compared to known, labeled outputs in the training data.
How Does Supervised Learning Work?
Supervised learning requires training data to be labeled. This means that each data point in the training set must have both input features (variables or attributes that describe the data point) and a corresponding output label (the desired output or target value associated with the input features). The labeling is usually done manually.
Supervised learning algorithms analyze the corresponding input-output pairs to identify patterns and relationships and then create a mapping function that links inputs to their respective outputs. The mapping function is what enables the model to make accurate predictions about new data.
To assess how well the model has learned, outputs can be compared with the actual values in the labeled data. Common metrics used for evaluation include F1-scores for classification tasks and R-squared for regression tasks.
Types of Supervised Learning
There are two main types of supervised learning tasks: classification and regression.
- Classification: Categorizes data into discrete classes or labels. The output is a discrete value that indicates a specific category or label.
- Regression: Predicts a continuous value based on the input data. The output is a number that can vary across a range of values.
Supervised Learning Use Cases
Supervised learning is useful for grouping data into specific categories (classification) and understanding the relationship between variables to make predictions (regression). This type of machine learning plays an important role in a wide variety of AI fields of study that rely on predictive modeling, including computer vision, generative AI (genAI), natural language processing (NLP), robotics, and deep learning.
Supervised learning is also used to fine-tune generative AI models for specific types of AI content generation. For example, fine-tuning can ensure a large language model’s (LLM) outputs follow a specific AI copywriting style or format.
Supervised Learning vs. Unsupervised Learning & Semi-Supervised Learning
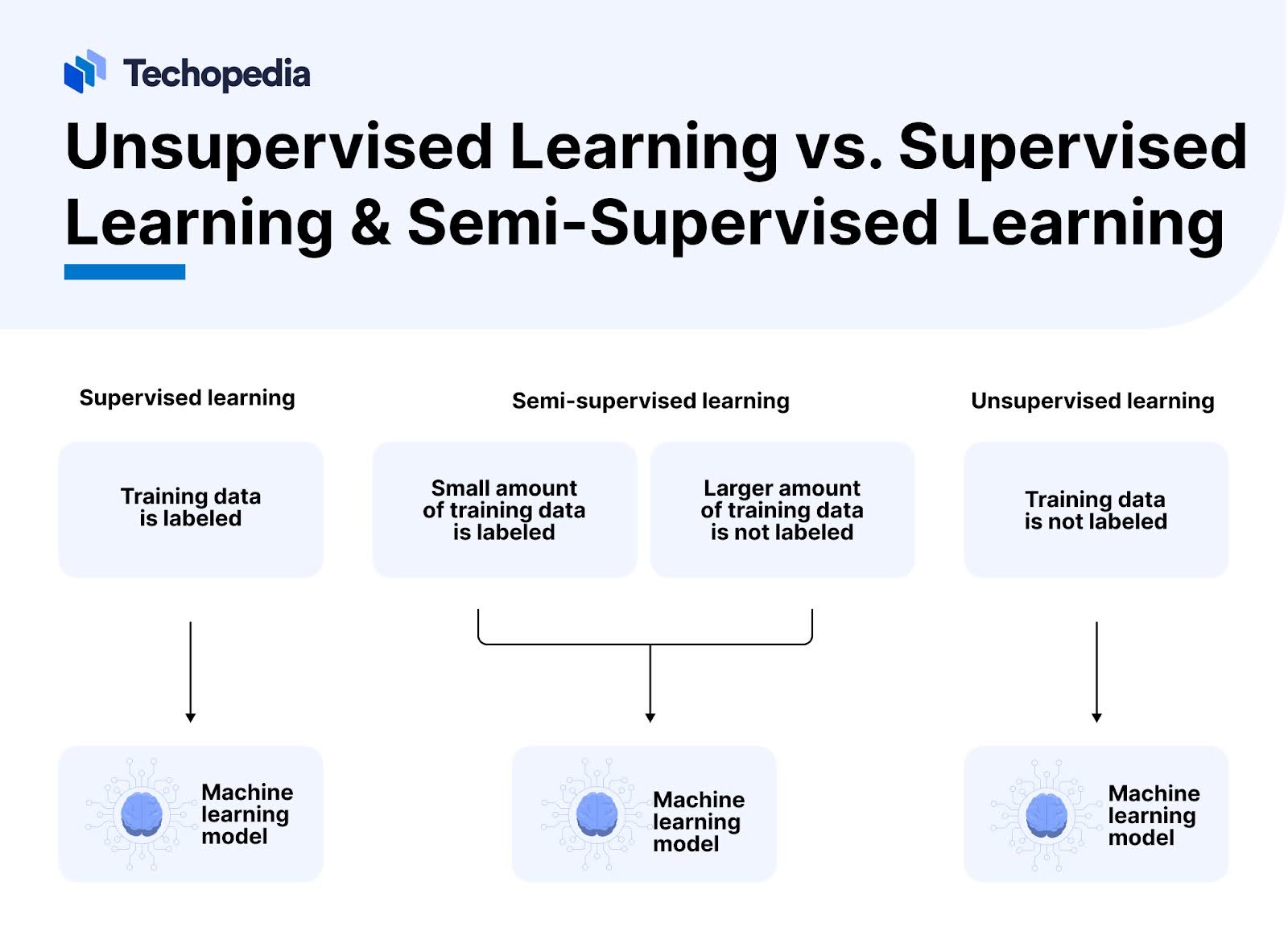
Unsupervised learning, supervised learning, and semi-supervised learning are the three main types of machine learning.
Supervised Learning Algorithms
Supervised learning algorithms are designed to learn from labeled data by analyzing input-output pairs and identifying patterns and relationships.
The choice of supervised learning algorithm depends on factors like task type (classification or regression), the amount of available training data, the complexity of patterns in the data, and computational resources.
For example, a linear regression algorithm might be best for simple numerical predictions, while support vector machines may be good for more complex tasks like image classification. Each algorithm has its trade-offs in terms of accuracy, interpretability, and computational efficiency.
Supervised Learning Algorithm Examples
Here are some examples of different supervised learning algorithms and what they are used for:
Used for regression tasks where the relationship between inputs and outputs is approximately linear.
Primarily used for binary classification tasks where the output is one of two classes.
Used to split data into branches that ultimately lead to a prediction. Used for both classification and regression tasks.
Combines multiple decision trees to improve prediction accuracy. Used for both classification and regression tasks.
Helps classify data points into discrete categories with high precision. Used for image classification tasks where data can be separated with a clear boundary.
Assigns an input to the category of the nearest labeled data points (neighbors). The “K” in KNN represents the number of neighbors considered for making a prediction.
Classifies data based on probabilities, with the “naive” assumption that the features are independent of each other. Used for natural language processing in text classification tasks like spam filtering.
Supervised Learning Pros and Cons
Supervised learning is a powerful tool for predictive modeling. However, it also comes with its own set of limitations.
Pros
- Achieves high accuracy with sufficient high-quality labeled data
- Supports a variety of tasks across finance, e-commerce, healthcare, entertainment, and marketing
- Simplifies the interpretation of models like linear regression and decision trees
Cons
- Requires labeled data, which can be expensive and time-consuming
- Faces risk of overfitting with insufficient training data
- Struggles with inputs that differ significantly from their training data, limiting generalization
- Demands expensive computational resources for deep learning models
The Bottom Line
Supervise learning is defined by the way it uses labeled data sets to train algorithms that can classify data or predict outcomes accurately. This can be contrasted with unsupervised learning, where the algorithm explores unlabeled data to discover hidden structures and patterns without explicit guidance.
Combining both approaches can be highly effective. Unsupervised learning can be used to pre-process data and extract meaningful features that can be fed into a supervised learning model to improve its ability to generalize and generate more accurate outputs.
FAQs
What is supervised learning in simple terms?
What is supervised vs. unsupervised learning?
What are the two types of supervised learning?
What best describes supervised learning?
References
- How Machine Learning Algorithms Work (they learn a mapping of input to output) – MachineLearningMastery.com (Machinelearningmastery)
- R-Squared – Definition, Interpretation, Formula, How to Calculate (Corporatefinanceinstitute)
- Machine Learning Regression Explained – Seldon (Seldon)




















