
















As your organization expands, you may be considering the need for and benefits of an automated anomaly detection system — especially if your business relies on a complex user-facing or customer-facing application.
An early-warning system that tracks deviations from normal behavior will help you avoid unplanned downtime, lost productivity and customer dissatisfaction, as well as help with forecasting.
The sticking point of course isn’t how an anomaly is defined, but how normalcy is defined.
In a time series, your anomaly detection system is looking at data as soon as it comes in, one data point at a time. It then must essentially make an instantaneous decision as to whether the new data is consistent with a model of normalcy.
Learning the normal behavior of time series isn’t just used for anomaly detection. Once you establish what normal behavior looks like, you’ll be able to create an algorithm that uses time series data from the past and extrapolates that information to project what the metric may look like in the future — known as forecasting.
Businesses currently use forecasting to anticipate revenue, website visitors, conversions, ROI and other KPIs that are important to growth and inventory planning.
Ordinarily, normality is determined using a statistical test. You find a series of data, create a normal distribution and flag data points that fall outside of that distribution.
This is a simple statistical technique, however, and it will produce too many false positives to be workable in an enterprise environment.
So how do you scale your anomaly detection as your KPIs and metrics become increasingly complicated?
Let’s cover some of the best ways to find normal values for your data and which pitfalls to avoid.
One Size Doesn’t Fit All
One model won’t fit every type of data pattern. There are different types of data, which generate different patterns. One model won’t be able to fit every kind of data. In addition, not every kind of data produces a smooth and orderly pattern, as shown in the top left figure below.
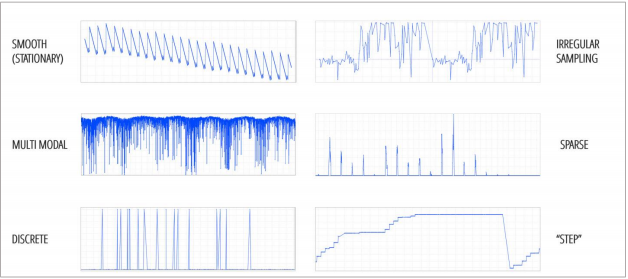
Figure 1: A sampling of time series models.
And to make things more complicated, one type of KPI or metric won’t always fit into one category. It can easily switch from behaving like one model to behaving like another — from a multi-modal signal to a stepwise signal, for example.
And it can happen rapidly and without warning.
The ideal anomaly detection system will have multiple models at play, which can follow fluctuating behavior based on data seasonality, trends, etc.
Factoring in Seasonality
Let’s say for example that you’re an online retailer and you see a pattern in your data — a spike in orders during the morning and a larger spike in the evening when people get home from work. Sometime in June, you start getting alerts on orders that take place throughout the day.
Is something wrong? Not necessarily. College students are home for the summer, and they’re taking advantage of their free time. This is just one way patterns in your metrics can change.
The example above shows hallmarks of seasonality. What do I mean by seasonality? These are patterns seen in time series data that repeat themselves regularly.
Multiple kinds of seasonality can affect a single stream of data. For example, a pizza store may see sudden surges in sales at lunch and at dinner, on weekends and on the first day of summer break. These are all examples of seasonality, at the daily, weekly, and annual level. These aren’t anomalies because they occur regularly and therefore can be anticipated.
The system below learns seasonality, and anticipates it.
See the baseline below.
Rather than a wide sleeve, the blue area is narrow and fluctuates with the data, following trends quite precisely. This stands in sharp contrast to static thresholds, which would typically be set to encapsulate all the data.
This kind of system would miss the anomalies highlighted below. These dips clearly deviate from the normal pattern, but they wouldn’t be detected by a model that doesn’t account for seasonality.
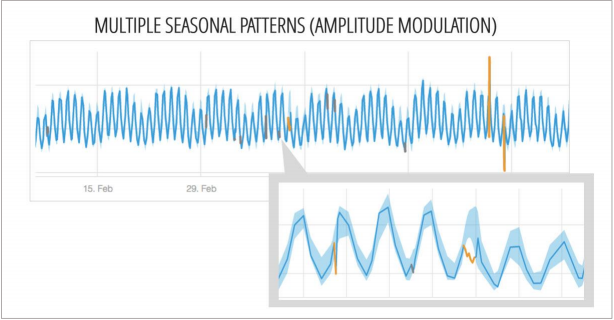
Figure 2: A graph that shows subtle anomalies that would easily go undetected with static thresholds.
Building the Right Model
Special Events
Not all models are designed to integrate information such as special events and those data points will appear anomalous. As such, those models shouldn’t be used when the events influence the data significantly.
In the eCommerce graph below, the total sales from Amazon Prime Day (mid-July) deviates substantially from the normal behavior. If the retailer were to use a model that does not account for influencing events, this data would trigger a false positive (for an anomaly detection system) and would produce a very high error rate for a forecast.
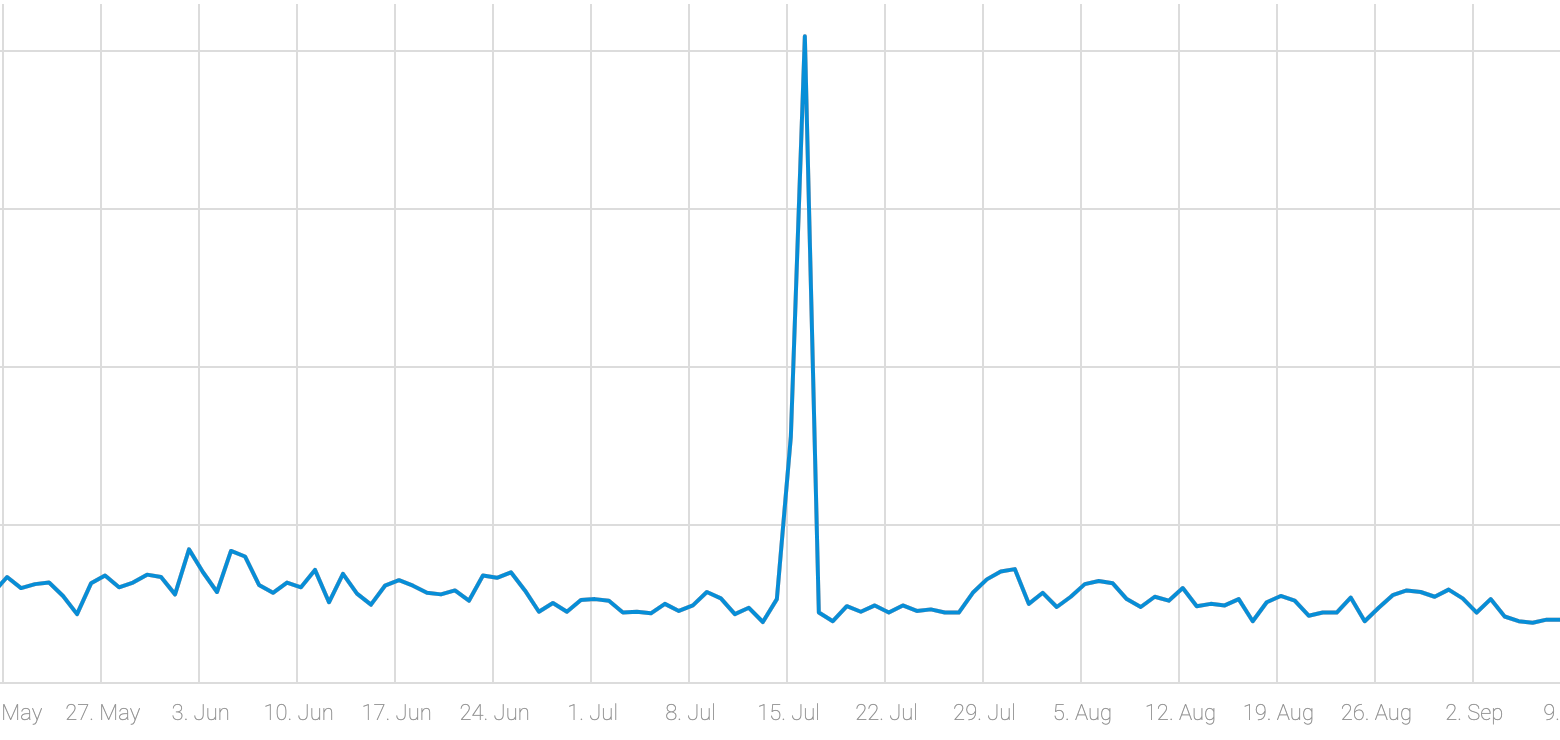
Figure 3: A significant jump in sales marked by a special event – in this case, Amazon Prime Day.
Non-Linearity
Linear models such as Holt Winters and ARIMA can do a pretty good job for many metrics, but cannot account for non-linear trends and irregular sampling intervals in the data. In this case non-linear models might be required.
In the figure below, the first quadrant shows linear growth and could very well be modeled with Holt Winters or ARIMA. But as time progresses, the data grows at a more exponential rate, and your anomaly detection or forecasting system would need to change to a non-linear model.
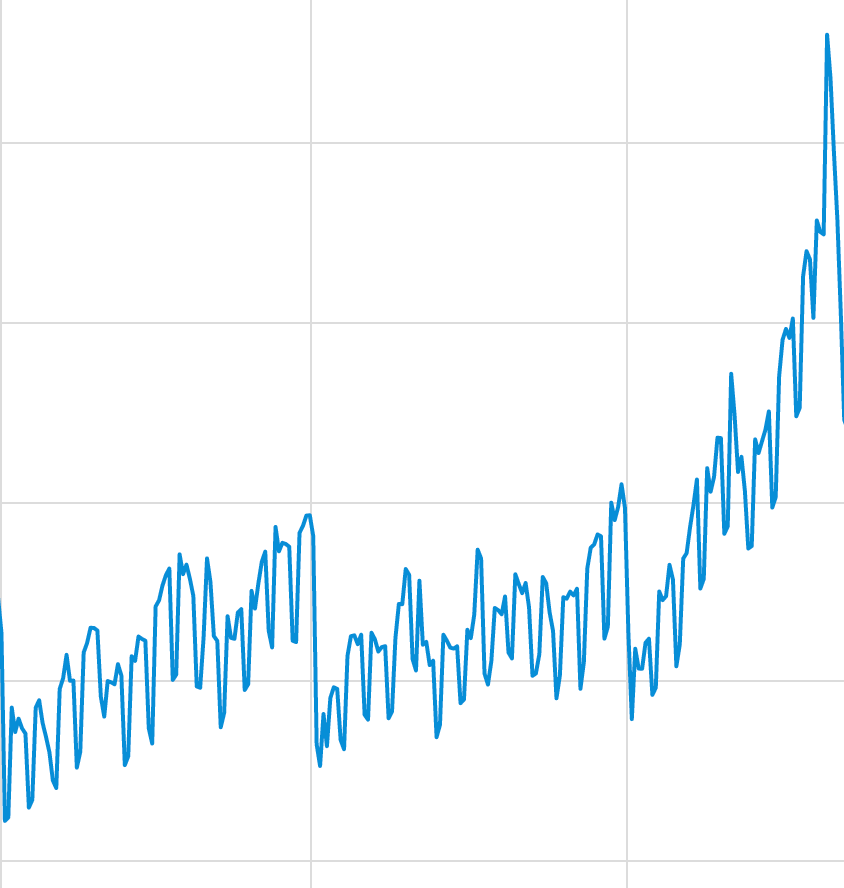
Figure 4: Data that shows non-linear growth.
In some cases, however, you can still use a linear model for a seemingly exponential rate of growth by switching to the logarithmic scale.
When measuring the initial cases of Coronavirus worldwide, the graph is clearly exponential, but a linear model could make a pretty accurate estimation if applied to that graph’s logarithmic scale.
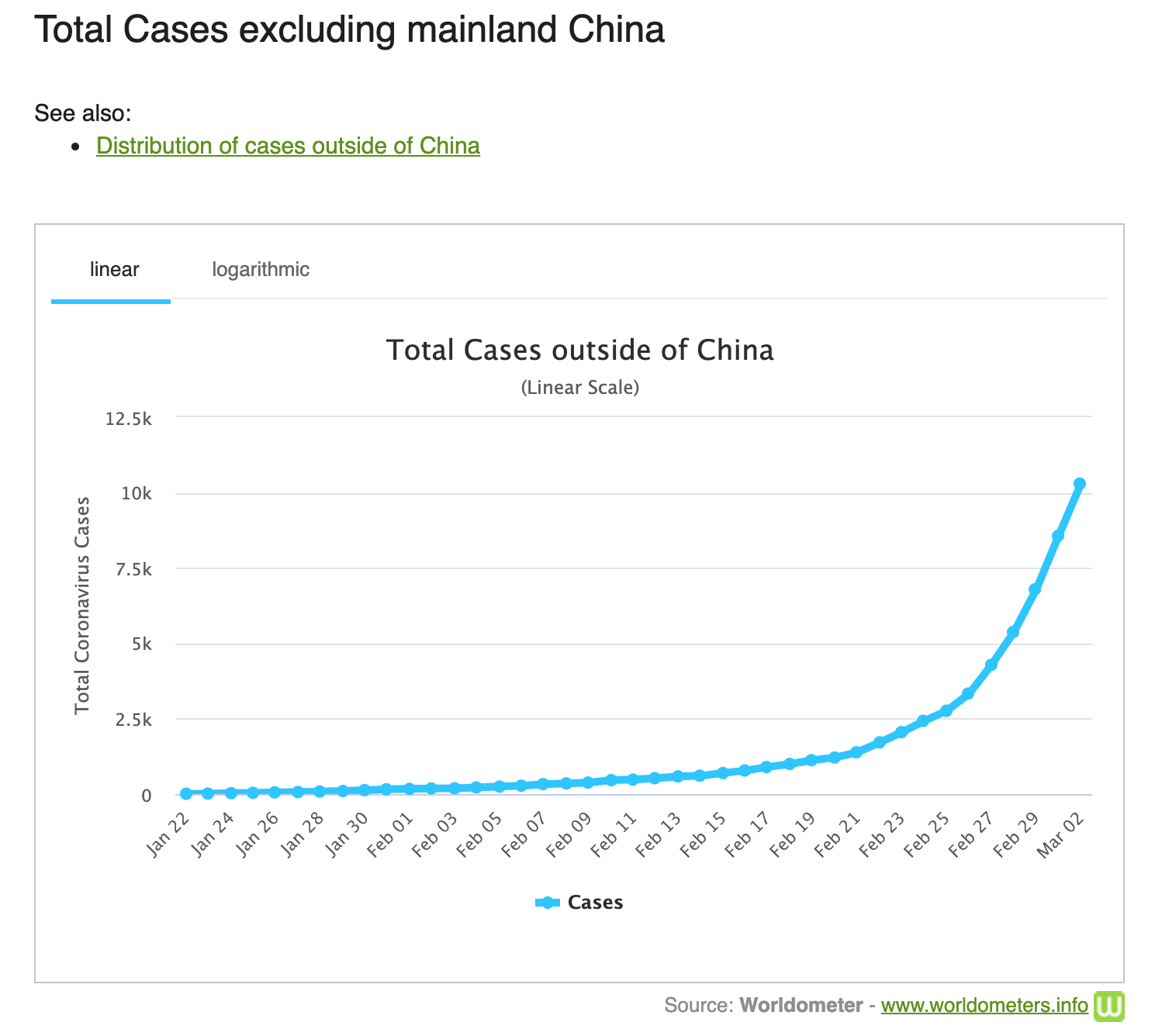
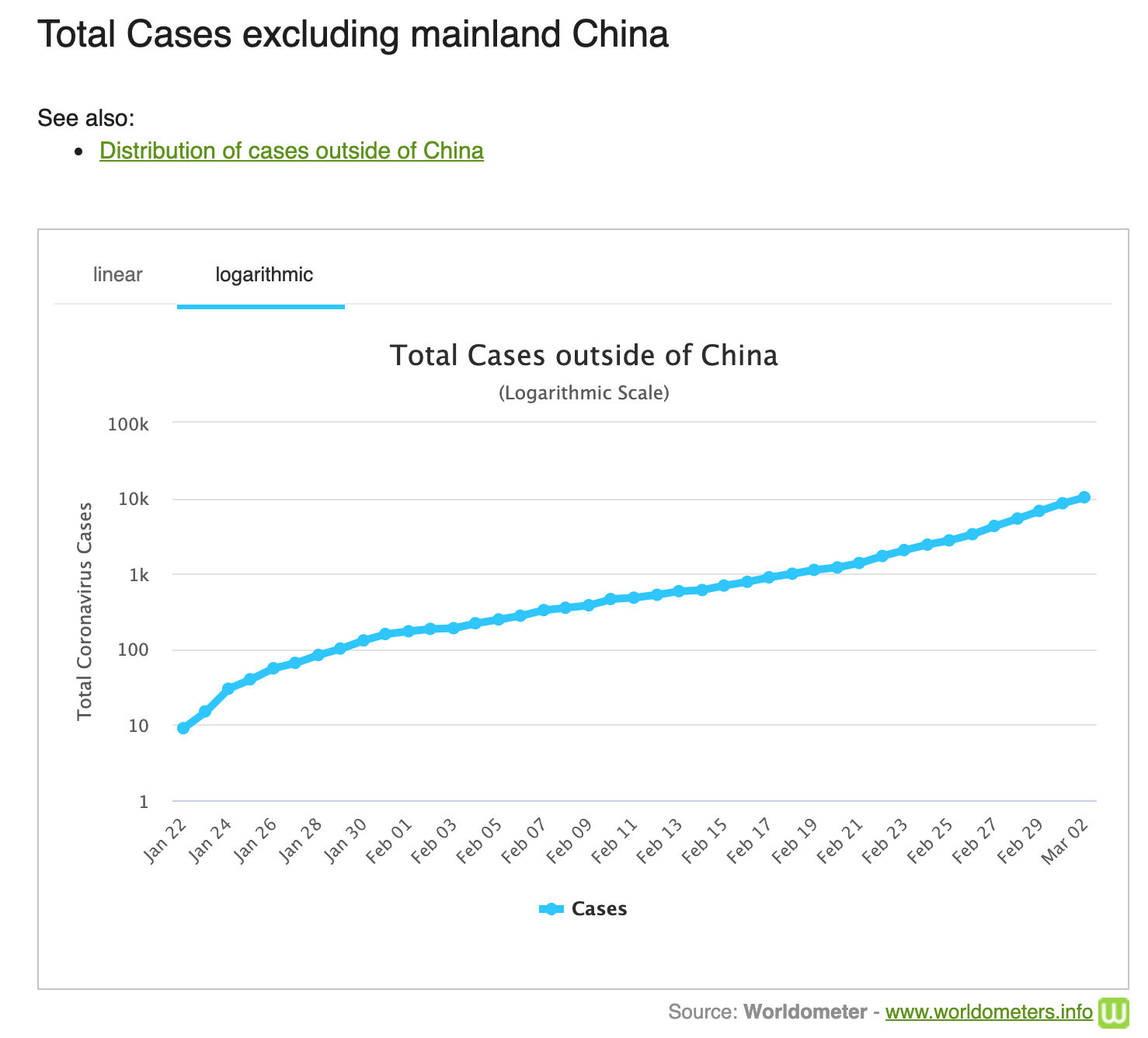
Figure 5: The graph on the left shows exponential growth. Its logarithmic equivalent shows more linear growth. Source: Worldometer.info
We’ve covered seasonality, influencing data and non-linearity. But how do you account for these factors? Artificial neural networks (ANN) prove useful here (specifically RNN/LSTM) but training a an ANN takes quite a bit of resources, so you may find that it’s only worthwhile to do this for your top KPIs.
In some cases, you may find a single KPI or metric alternates between multiple distributions more than once (see the “multi modal” data in Figure 1). For that, a mixture of models may be needed (e.g., GMM in simple cases).
And lastly, your organization may be monitoring many different types of metrics, and for that you’ll need a mechanism which automatically decides which model to train on each type of data.
Automation is the Only Way to Go at Scale
Given that 15% of metrics involve seasonality, having models that don’t account for data trends risks false positives and false negatives. If you monitor for anomalies using traditional methods, testing each metric for seasonality is going to add a considerable amount of time and effort to your work — which is why machine learning proves so effective.
If you have only 10 metrics to monitor, it might be possible to manually find models that will fit their individual signals, discern patterns of seasonality and switch models as needed when the signal changes.
Most businesses have more than 10 metrics they need to keep track of however, by several orders of magnitude. The only way to accurately monitor thousands to millions of metrics is with algorithms that fit models to signals, identify seasonal patterns and then readjust the models to the signal when needed.
So how does this work?
The ML system uses historical data to automatically identify seasonality and train an initial model for normality. Then it takes each new data point in the time series and determines whether it is normal. In an environment where even a “normal” signal can spike unpredictably, you can see the challenge involved in remaining accurate.
The trick is to use machine learning algorithms that constantly adapt. Every piece of new and “normal” time series data becomes part of an updated understanding of the signal.
When the pattern of the data changes, as in Figure 6 below, it will often deduce automatically that a new model must be trained to better fit the data.
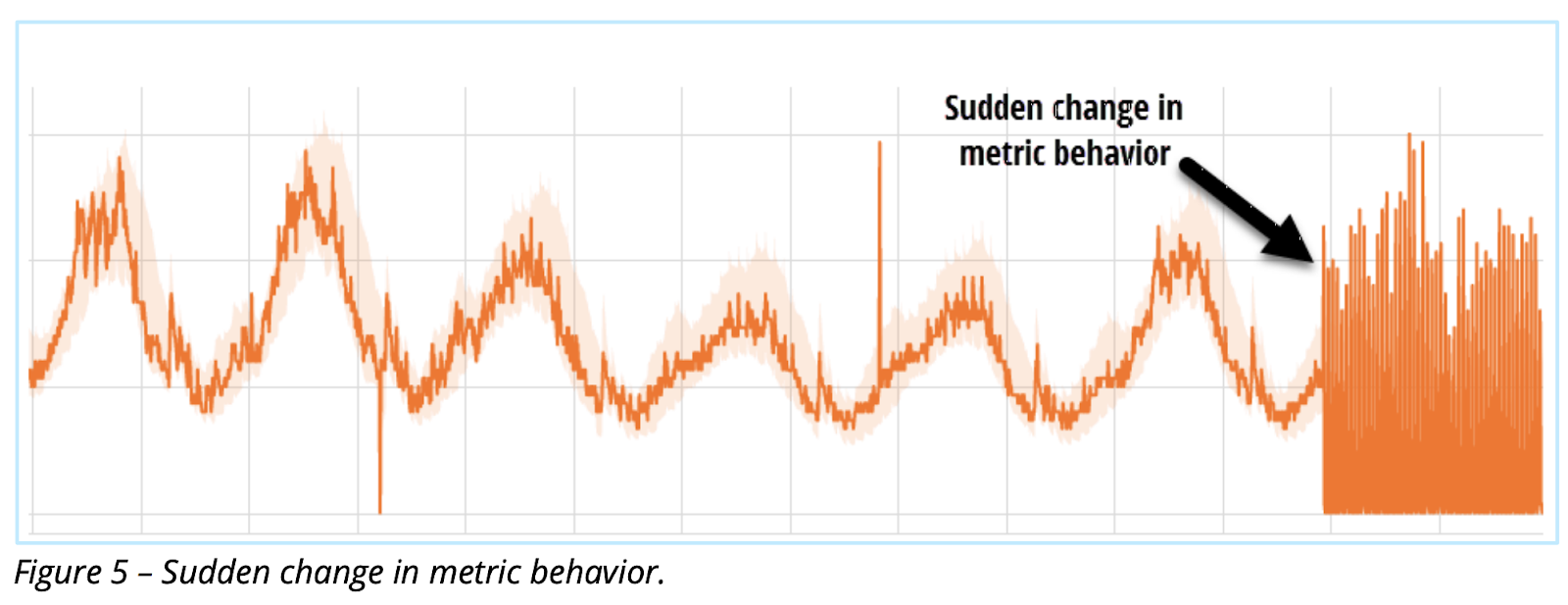
Figure 6: Sudden change in metric behavior.
Dodging the Pitfalls of Adaptive Learning
But adapting the model to every new data that arrives is not always desired. Occasionally the new data is anomalous. The challenge is to distinguish between cases where new data which doesn’t fit the normal behavior is anomalous, and cases where the data pattern is changing.
In the first case (see Figure 7), be careful not to update the model with the anomalous data, whereas in the second case (see Figure 8) we want the model to be adapted to the new pattern as quickly as possible.
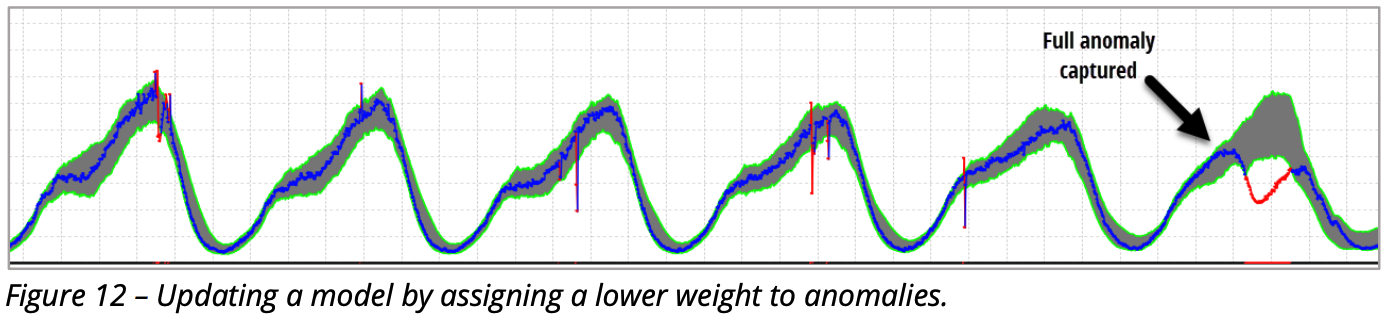
Figure 7: Updating a model by assigning a lower weight to anomalies.
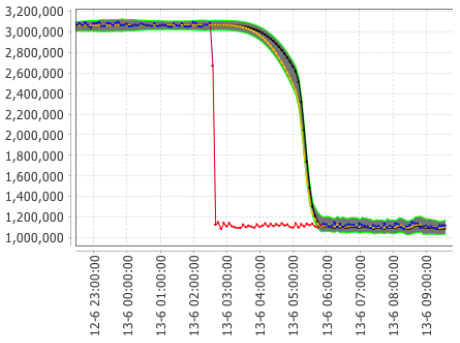
Figure 8: Model updates immediately to significant shift in data behavior.
Anomalies are identified as deviations from the normal behavior of the data, therefore until you have a representation of the normal behavior you cannot identify anomalies. But often those appear in the training data that is used to initialize the model.
Be careful not to integrate anomalies in our initial model in order to avoid misidentification of anomalies in the future. For example, if Black Friday falls in the training period of an online store’s demand metrics, the expected demand on Friday may appear significantly higher than the actual values.
Such extreme cases can be avoided using techniques such as outlier removal.
On the other hand, if your model can incorporate influencing factors, such as a special event like a holiday or a marketing campaign, then leave those anomalies in the training data, but be sure to label the event accordingly.
This is Just the Start
Building a model that accounts for normal behavior needs to factor in seasonality, special events and non-linearity, while also discounting anomalies — but that’s just the beginning.
Your system should be able to adjust to shifts in data patterns, some of which the model can be adapted to and others require a completely different model.





















