What is Big Data?
Big data is a large data set that is difficult to process and analyze with traditional methods. Most of the time, the term big data means a range of structured, unstructured, and semi-structured data.
It’s worth noting that the five V’s – volume, velocity, variety, veracity, and value – can be used to define big data and its characteristics (these are outlined further below).

Key Takeaways
- Big data is a term used to describe large datasets of structured, unstructured, and semi-structured data that are too difficult to process with traditional methods.
- You can identify big data with the five V’s; volume, velocity, variety, veracity, and value.
- Knowing how to collect and process big data is essential for powering modern business applications and AI models.
- Tech vendors like Microsoft, Google Cloud, and Amazon Web Services all offer solutions for collecting and processing large data sets.
- Processing big data can introduce new opportunities and risks.
Big Data Importance
So why is big data important? At its core, big data matters because it can provide valuable insights into an organization’s processes, which decision-makers can use to perform data analysis and find ways to improve operational efficiency.
For example, by collecting and aggregating a large data set, a CMO could better analyze customer behavior and market trends to inform their marketing strategy and optimize revenue.
Similarly, an e-commerce business could use its data to provide customers with more personalized offers and promotions.
Implementing big data basics and best practices also enables organizations to use powerful applications to monitor their operations including business analytics tools, predictive modeling, and machine learning (ML) models.
How Does Big Data Work?
If you want to understand how big data works, there are three main steps to focus on:
Integration
The first step involves integrating raw data from various sources of big data (this could be a CRM,a spreadsheet, or another source) and transforming it into a unified format that can be analyzed by human users.Storage
Once you’ve transformed the data, you’ll want to be able to store it. This can be done on-premises, in the cloud, or as part of a hybrid approach that mixes the two.Analysis
Now that your data is stored in one place you can start to use data analytics (DA) solutions with dashboards, graphs, and charts to identify patterns and trends.
5 V’s of Big Data
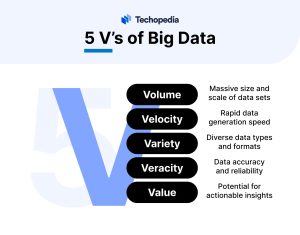
Big data can be identified by three V’s; variety, volume, and velocity. That being said, in recent years, this has grown to 5 V’s, as value and veracity have been added to the mix too.
A summary of the five V’s can be found below:
Types of Big Data
Now you know what big data is and how it works, we’re going to look at the different types of big data. Below is an overview of different types of big data assets:
A type of data that doesn’t have a structured database format. This includes emails, videos, photos, audio files, web pages, No-SQL databases, geospatial data, weather data, and more.
A type of data that has a standardized format. This includes relational data stored in tables with rows and columns in databases, hierarchical data, and tabular data stored in spreadsheets or data tables.
A type of data without a standardized format or schema, which has tags and other metadata that can help to analyze it. Examples include graphs and tables, Hypertext Markup Language (HTML) code, Extensible Markup Language (XML) documents, and JavaScript Object Notation (JSON).
Big Data Tools
Dealing with large data sets that contain a mixture of data types requires specialized tools and techniques tailored for handling and processing diverse data formats and distributed data structures. Popular tools include Azure Data Lake, Elasticsearch, Google Cloud, Redshift, and Tableau, which all provide a useful introduction to big data analytics.
Big Data and AI
Big data and artificial intelligence (AI) are tied closely together, because AI and machine learning models need access to large volumes of training data; they’re to be trained to detect patterns and make accurate predictions.
Generally, an organization that wants to use AI to process its data, needs to have integrated and stored it first.
Big Data Management Technologies
Big data management technologies can be broken down into a range of solution categories, from data management solutions to unified analytics platforms and data processing engines.
Some of the most popular big data management technologies include Cloudera, Google Cloud BigQuery, Databricks, Spark, Airflow, Hadoop, Cassandra, and Tableau. These tools all help determine how big data is used.
Big Data Use Cases
There are a wide range of use cases for big data.
Some of the most notable include:
Big Data Examples
Big data comes from a wide variety of sources across different industries and domains.
Below are some examples of sources for large data sets and the types of data they include.
| Big data source | Description |
|---|---|
| Customer data | Data is collected through CRM systems, including customer profiles, sales records, and customer interactions. |
| E-commerce transactions | Data generated from online retail platforms, including customer orders, product details, payment information, and customer reviews. |
| Financial transactions | Data obtained from banking systems, credit card transactions, stock markets, and other financial platforms. |
| Government and public data | Data provided by government agencies, census data, public transportation data and weather data. |
| Health and medical records | Data from electronic health records (EHRs), medical imaging, wearable health devices, clinical trials, and patient monitoring systems. |
| Internet of Things (IoT) devices | Data is collected from various IoT devices such as intelligent sensors, smart appliances, wearable devices, and connected vehicles. |
| Research and scientific data | Data from research experiments, academic studies, scientific observations, digital twin simulations, and genomic sequencing. |
| Sensor networks | Data gathered from environmental sensors, industrial machinery, traffic monitoring systems, and other wireless sensor networks. |
| Social media platforms | Data generated from social media platforms like Facebook, Twitter, Instagram, and LinkedIn, including posts, comments, likes, shares, and user profiles. |
| Web and mobile Applications | Data produced by users while interacting with websites, mobile apps, and online services, including clicks, page views, and user behavior. |
Big Data Regulations
While there isn’t a uniform set of regulations governing how data can be collected internationally, there is legislation that introduces legal requirements on how personal data can be collected and processed, which should guide big data strategy and solutions.
For example, the EU’s General Data Protection Regulation (GDPR) dictates that organizations holding the data of EU data subjects must be transparent with customers about how they collect and process customer data and only collect data that the user has consented to give them.
5 Big Data Best Practices

Now you know some of the core big data concepts, let’s look at some of the best practices you can follow to get the most out of your data.
Some of these include:
Outline clear objectives you want to achieve by using your data. For instance, a basic goal could be to increase the conversion rate of your marketing outreach by X%.
Offer employees training to make sure they know how to get the most out of data analytics solutions.
Complete a risk assessment to make sure that your data handling practices are in compliance with regulations like the GDPR.
Secure your data with best practices such as data encryption and zero trust authentication.
Implement a data governance strategy to help comply with data protection regulations and better organize your data assets.
Big Data Challenges and Benefits
The biggest challenge of adopting big data is how complex the ingesting process is. You not only need to be able to find data generated in your environment, but you need to be able to ingest it and format it in a way that it can be understood by data analytics tools.
This process takes a significant amount of time and money but is well worth it as you can start to unlock insights into how to improve your business operations that you wouldn’t have without it.
Big Data Future
Arguably the biggest trend to watch in big data is an increase in data volume. The number of Internet of Things devices is expected to reach 32.1 billion by 2030, so there will be more and more touchpoints generating data that organizations need to be able to process, particularly if they want to make use of emerging technologies like AI.
The Bottom Line
Now you know the definition of big data it’s worth noting that there’s no one size fits all for every organization. The journey toward understanding big data is different for each company, as each business generates different types of data and has different long- term goals for using it.