

















What is Unsupervised Learning?
Unsupervised learning is a type of machine learning (ML) that allows an artificial intelligence (AI) model to learn from data without any human guidance. Unsupervised learning algorithms can discover patterns and detect anomalies in unstructured and structured data without the need for training data to be labeled.

Key Takeaways
- The primary goal of unsupervised learning is to discover patterns, relationships, and structures in data without relying on pre-existing labels.
- Unsupervised learning uses clustering, association rules, and dimensionality reduction algorithms to gain insights into unlabeled data.
- Common techniques in unsupervised learning include grouping similar data points (clustering), identifying relationships or rules within data (association analysis), and simplifying data by reducing the number of variables (dimensionality reduction).
- Unsupervised learning can be used as a preliminary step in machine learning pipelines to understand a large dataset before applying more structured learning techniques.
- Unsupervised learning can be challenging because it’s difficult to assess model accuracy without labeled data, and hyperparameters often require significant tuning to produce meaningful results.
Examples of Unsupervised Learning Algorithms
Unsupervised learning algorithms are characterized by their ability to learn from unlabeled data, their focus on exploration and pattern discovery, and their capacity to reveal hidden structures and insights that might otherwise remain unknown.
- Clustering algorithms like k-means can group data points based on their similarity in terms of distance or density
- Association rule learning algorithms like Apriori can find relationships between variables, such as “customers who bought this also bought that”
- Techniques like Principal Component Analysis (PCA) can reduce the number of variables while preserving important information and make it easier to visualize and analyze data
- Algorithms like Gaussian Mixture Models (GMM) can model the underlying probability distribution of the data to identify hidden patterns and structures
How Does Unsupervised Learning Work?
Unsupervised learning algorithms can analyze unlabeled data to identify underlying data structures, recognize data patterns, and discover relationships between data points. Grouping similar data points and calculating how closely they relate to each other helps reveal meaningful insights without needing labeled data.
Machine learning libraries are essential tools for implementing unsupervised learning. They provide the building blocks and frameworks that make it easier to develop, train, and deploy unsupervised learning models.
Machine Learning Libraries That Support Unsupervised Learning
Scikit-Learn, TensorFlow, Pytorch, and Keras are popular machine learning libraries that provide tools for building and deploying unsupervised machine learning models.
Types of Unsupervised Learning
Different types of unsupervised learning use different techniques to discover and represent patterns in data. The two primary types of unsupervised learning are clustering and association.
Clustering groups similar data points together based on their characteristics. Association identifies relationships between variables.
Dimensionality reduction can be used to reduce the number of variables and dimensions within the data. This not only conserves processing power, it also helps prevent overfitting and makes it easier to identify patterns, relationships, and anomalies.
Applications of Unsupervised Learning in the Real World

Unsupervised learning is a powerful tool for extracting insights from unlabeled data and solving real-world problems across various domains.
Here are some practical use cases for unsupervised learning in the real world:
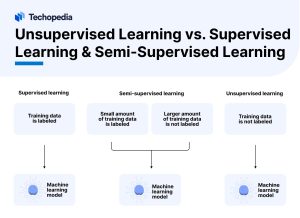
Unsupervised Learning vs. Supervised Learning & Semi-Supervised Learning
Unsupervised learning, supervised learning, and semi-supervised learning are the three main types of machine learning:
- Supervised learning algorithms: Compare model outputs to corresponding output labels. Unsupervised learning algorithms: Explore the data to identify patterns, clusters, or relationships without any supervision.
- Semi-supervised algorithms are initially trained on a small amount of labeled data before they are given a larger amount of unlabeled data to explore.
Challenges and Benefits of Unsupervised Learning
Unsupervised learning can be used to uncover hidden patterns in data, but its use comes with its own set of challenges and benefits.
Benefits:
- Can uncover hidden patterns, relationships, and anomalies in structured and unstructured data that might not be apparent through traditional analysis methods.
- Unsupervised learning algorithms allow businesses and researchers to take advantage of the vast amount of unstructured data that humans produce each day.
- Can be used to learn the relevant features of a large data set, and this knowledge can then be used as input for supervised learning models.
Challenges:
- The outputs for unsupervised learning algorithms are subjective because the algorithms draw their own conclusions. This can make the logic behind outputs difficult to understand and explain.
- Unsupervised learning algorithms require significant computational resources to analyze high-dimensional data and extremely large datasets. This can be time-consuming and computationally expensive.
- As the volume of the data space grows, it can be difficult for unsupervised algorithms to differentiate between meaningful patterns and noise. Determining the optimal number of clusters or relationships can also be difficult and require trial and error or the use of additional techniques to validate results.
Future of Unsupervised Learning
The future of unsupervised learning is being driven by an increasing volume of unlabeled data and the need for more data to train the large language models (LLMs) that power AI content generators and AI writing tools.
Important trends include a greater focus on explainability, more integration with deep learning, and ethical considerations regarding both the unauthorized use of data for training purposes and the environmental impact of AI power requirements.
While unsupervised learning is readily available today through machine learning frameworks and platforms like Scikit-Learn, TensorFlow, PyTorch, and Keras, this type of machine learning still requires expertise to select the right models, tune hyperparameters, and interpret results.
The Bottom Line
Unsupervised learning, by definition, is a type of machine learning that can discover patterns, relationships, and anomalies in large datasets without human supervision. Unsupervised learning algorithms are especially useful in scenarios where manually labeling data would be impractical or impossible.




















