The Skeptics Club
If you, like me, belong to the skeptics club, you also might have wondered what all the fuss is about deep learning. Neural networks (NNs) are not a new concept. The multilayer perceptron was introduced in 1961, which is not exactly only yesterday.
But current neural networks are more complex than just a multilayer perceptron; they can have many more hidden layers and even recurrent connections. But hold on, don’t they still use the backpropagation algorithm for training?
Yes! Now, machine computational power is incomparable to what was available in the ’60s or even in the ’80s. This means much more complex neural architectures can be trained in a reasonable time.
So, if the concept is not new, can this mean that deep learning is just a bunch of neural networks on steroids? Is all the fuss simply due to parallel computation and more powerful machines? Often, when I examine so-called deep learning solutions, this is what it looks like. (What are some practical, real-world uses for neural networks? Find out in 5 Neural Network Use Cases That Will Help You Understand the Technology Better.)
As I said, though, I belong to the skeptics club, and I am usually wary of not-yet-supported evidence. For once, let’s set aside the prejudice, and let’s try a thorough investigation of the newly emerging techniques in deep learning with respect to neural networks, if any.
When digging a bit deeper, we do find a few new units, architectures and techniques in the field of deep learning. Some of these innovations carry a smaller weight, like the randomization introduced by a dropout layer. Some others, however, are responsible for more important changes. And, surely, most of them rely on the larger availability of computational resources since they are quite computationally expensive.
In my opinion, there have been three main innovations in the field of neural networks that have strongly contributed to deep learning gaining its current popularity: convolutional neural networks (CNNs), long short-term memory (LSTM) units and generative adversarial networks (GANs).
Convolutional Neural Networks (CNNs)
The big bang of deep learning – or at least when I heard the boom for the first time – happened in an image recognition project, the ImageNet Large Scale Visual Recognition Challenge, in 2012. In order to recognize images automatically, a convolutional neural network with eight layers – AlexNet – was used. The first five layers were convolutional layers, some of them followed by max-pooling layers, and the last three layers were fully connected layers, all with a non-saturating ReLU activation function. The AlexNet network achieved a top-five error of 15.3%, more than 10.8 percentage points lower than that of the runner up. It was a great accomplishment!
Besides the multilayer architecture, the biggest innovation of AlexNet was the convolutional layer.
The first layer in a convolutional network is always a convolutional layer. Each neuron in a convolutional layer focuses on a specific area (receptive field) of the input image and through its weighted connections acts as a filter for the receptive field. After sliding the filter, neuron after neuron, over all the image receptive fields, the output of the convolutional layer produces an activation map or feature map, which can be used as a feature identifier.
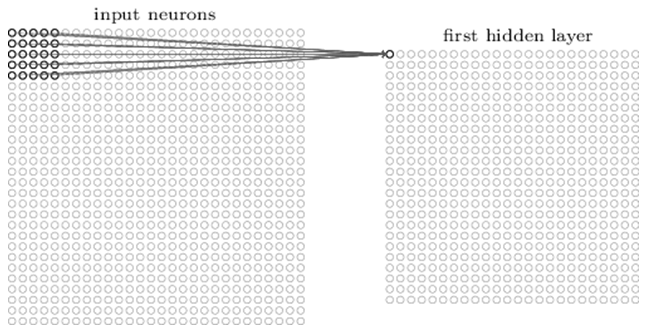 Figure 1. Neuron in a convolutional layer acting as a filter on a 5×5 receptive field of the input image (reproduced from Adit Deshpande’s “A Beginner’s Guide To Understanding Convolutional Neural Networks”).
Figure 1. Neuron in a convolutional layer acting as a filter on a 5×5 receptive field of the input image (reproduced from Adit Deshpande’s “A Beginner’s Guide To Understanding Convolutional Neural Networks”).
By adding more convolutional layers on top of each other, the activation map can represent more and more complex features from the input image. In addition, often in a convolutional neural network architecture, a few more layers are interspersed between all these convolutional layers to increase the nonlinearity of the mapping function, improve the robustness of the network and control overfitting.
Now that we can detect high-level features from the input image, we can add one or more fully connected layers to the end of the network for traditional classification. This last part of the network takes the output of the convolutional layers as input and outputs an N-dimensional vector, where N is the number of classes. Each number in this N-dimensional vector represents the probability of a class.
Back in the day, I often heard the objection to neural networks about the lack of transparency of their architecture and the impossibility to interpret and explain the results. This objection is coming up less and less often nowadays in connection with deep learning networks. It looks as if now it is acceptable to trade the black-box effect for higher accuracy in classification.
Long Short-Term Memory (LSTM) Units
Another big improvement produced by deep learning neural networks has been seen in time series analysis via recurrent neural networks (RNNs).
Recurrent neural networks are not a new concept. They were already used in the ’90s and trained with the backpropagation through time (BPTT) algorithm. In the ’90s though, it was often impossible to train them given the amount of computational resources required. However, nowadays, due to the increase in available computational power, it has become not only possible to train RNNs but also to increase the complexity of their architecture. Is that all? Well, of course not.
In 1997, a special neural unit was introduced to deal better with the memorization of the relevant past in a time series: the LSTM unit. Through a combination of internal gates, an LSTM unit is capable of remembering the relevant past information or forgetting the irrelevant past content in a time series. An LSTM network is a special type of recurrent neural network, including LSTM units. The unfolded version of an LSTM-based RNN is shown in Figure 2.
To overcome the problem of limited long memory capability, LSTM units use an additional hidden state – the cell state C(t) – derived from the original hidden state h(t). C(t) represents the network memory. A particular structure, called gates, allows you to remove (forget) or add (remember) information to the cell state C(t) at each time step based on the input values x(t) and the previous hidden state h(t−1). Each gate decides which information to add or delete by outputting values between 0 and 1. By multiplying the gate output pointwise by the cell state C(t−1), information is deleted (output of gate = 0) or kept (output of gate = 1).
In Figure 2, we see the network structure of an LSTM unit. Each LSTM unit has three gates. The “forget gate layer” at the beginning filters out the information from the previous cell state C(t−1) based on the current input x(t) and the previous cell’s hidden state h(t−1). Next, the combination of an “input gate layer” and of a “tanh layer” decides which information to add to the previous, already filtered, cell state C(t−1). Finally, the last gate, the “output gate,” decides which of the information from the updated cell state C(t) ends up in the next hidden state h(t).
For more details about LSTM units, check the GitHub blog post “Understanding LSTM Networks” by Christopher Olah.
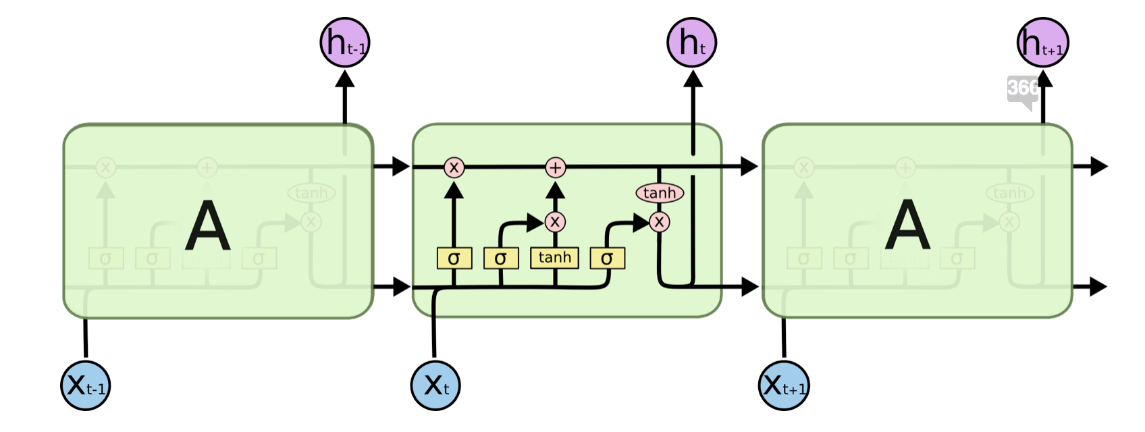 Figure 2. Structure of an LSTM cell (reproduced from “Deep Learning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville). Notice the three gates within the LSTM units. From left to right: the forget gate, the input gate, and the output gate.
Figure 2. Structure of an LSTM cell (reproduced from “Deep Learning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville). Notice the three gates within the LSTM units. From left to right: the forget gate, the input gate, and the output gate.
LSTM units have been used successfully in a number of time series prediction problems, but especially in speech recognition, natural language processing (NLP), and free text generation.
Generative Adversarial Networks (GAN)
A generative adversarial network (GAN) is composed of two deep learning networks, the generator and the discriminator.
A generator G is a transformation that transforms the input noise z into a tensor – usually an image – x (x=G(z)). DCGAN is one of the most popular designs for the generator network. In CycleGAN networks, the generator performs multiple transposed convolutions to upsample z to eventually generate the image x (Figure 3).
The generated image x is then fed into the discriminator network. The discriminator network checks the real images in the training set and the image generated by the generator network and produces an output D(x), which is the probability that image x is real.
Both generator and discriminator are trained using the backpropagation algorithm to produce D(x)=1 for the generated images. Both networks are trained in alternating steps competing to improve themselves. The GAN model eventually converges and produces images that look real.
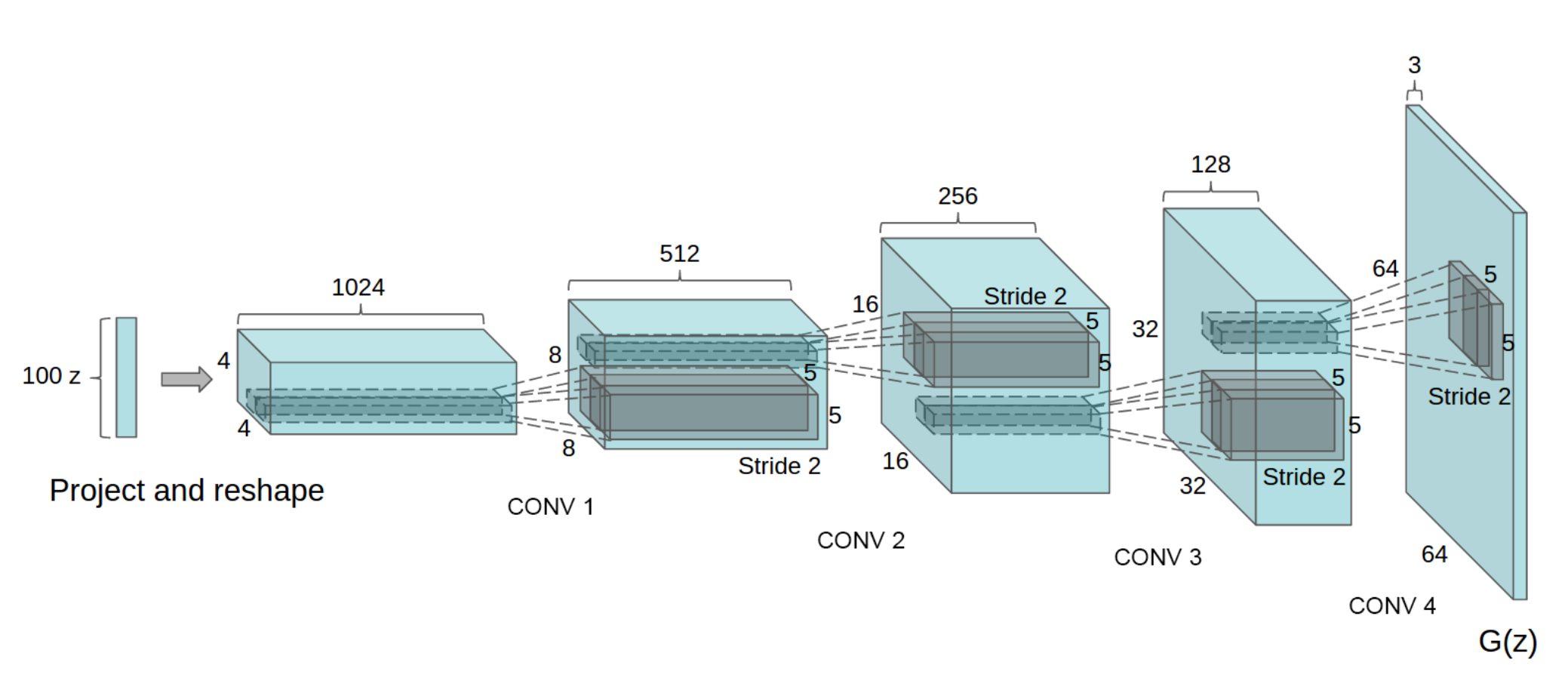 Figure 3. A DCGAN generator (reproduced from Jonathan Hui’s “GAN — What is Generative Adversary Networks GAN?”).
Figure 3. A DCGAN generator (reproduced from Jonathan Hui’s “GAN — What is Generative Adversary Networks GAN?”).
GANs have been successfully applied to image tensors to create anime, human figures, and even van Gogh-like masterpieces. (For other modern uses of neural networks, see 6 Big Advances You Can Attribute to Artificial Neural Networks.)
Conclusions
So, is deep learning just a bunch of neural networks on steroids? Partially.
While it is undeniable that faster hardware performances have contributed largely to the successful training of more complex, multi-layer and even recurrent neural architectures, it is also true that a number of new innovative neural units and architectures have been proposed in the field of what is now called deep learning.
In particular, we have identified convolutional layers in CNNs, LSTM units and GANs as some of the most meaningful innovations in the field of image processing, time series analysis and free text generation.
The only thing left to do at this point is to dive deeper and learn more about how deep learning networks can help us with new robust solutions for our own data problems.