
















What is Expectation Maximization?
Expectation Maximization, EM for short, is a statistical algorithm used for estimating parameters in statistical models, particularly when your data set contains incomplete or hidden information.
The algorithm’s key feature is its ability to find maximum likelihood estimates for model parameters – the values that make the observed data most probable – which is a central task in many statistical applications.
The roots of the EM algorithm trace back to the 1970s. It was formulated by Arthur Dempster, Nan Laird, and Donald Rubin in their seminal 1977 paper. Their work consolidated various statistical estimation methods under a single, more generalized framework. This was a significant advancement, as it provided a systematic way to approach and solve a wide range of complex statistical problems that were previously tackled by more ad-hoc methods.
The Expectation Maximization Algorithm, Explained
The basic concept of the EM algorithm involves iteratively applying two steps: the Expectation (E) step and the Maximization (M) step.
In the E-step, the algorithm estimates the missing or hidden data based on a current estimate of the model parameters. Then, in the M-step, it updates the model parameters to maximize the likelihood of the data, including the newly estimated values.
This process repeats, with each iteration improving the parameter estimates and getting closer to the maximum likelihood solution.
In data analysis, EM is very useful when dealing with incomplete datasets or when modeling complex phenomena that involve latent variables (variables that are not directly observed but are inferred from other variables). It’s a versatile tool used in various fields like machine learning, computer vision, bioinformatics, and economics.
The algorithm’s ability to handle data with missing elements without having to discard or impute missing values artificially makes it a valuable technique for extracting insights from incomplete or imperfect datasets.
How Expectation Maximization Algorithm Works
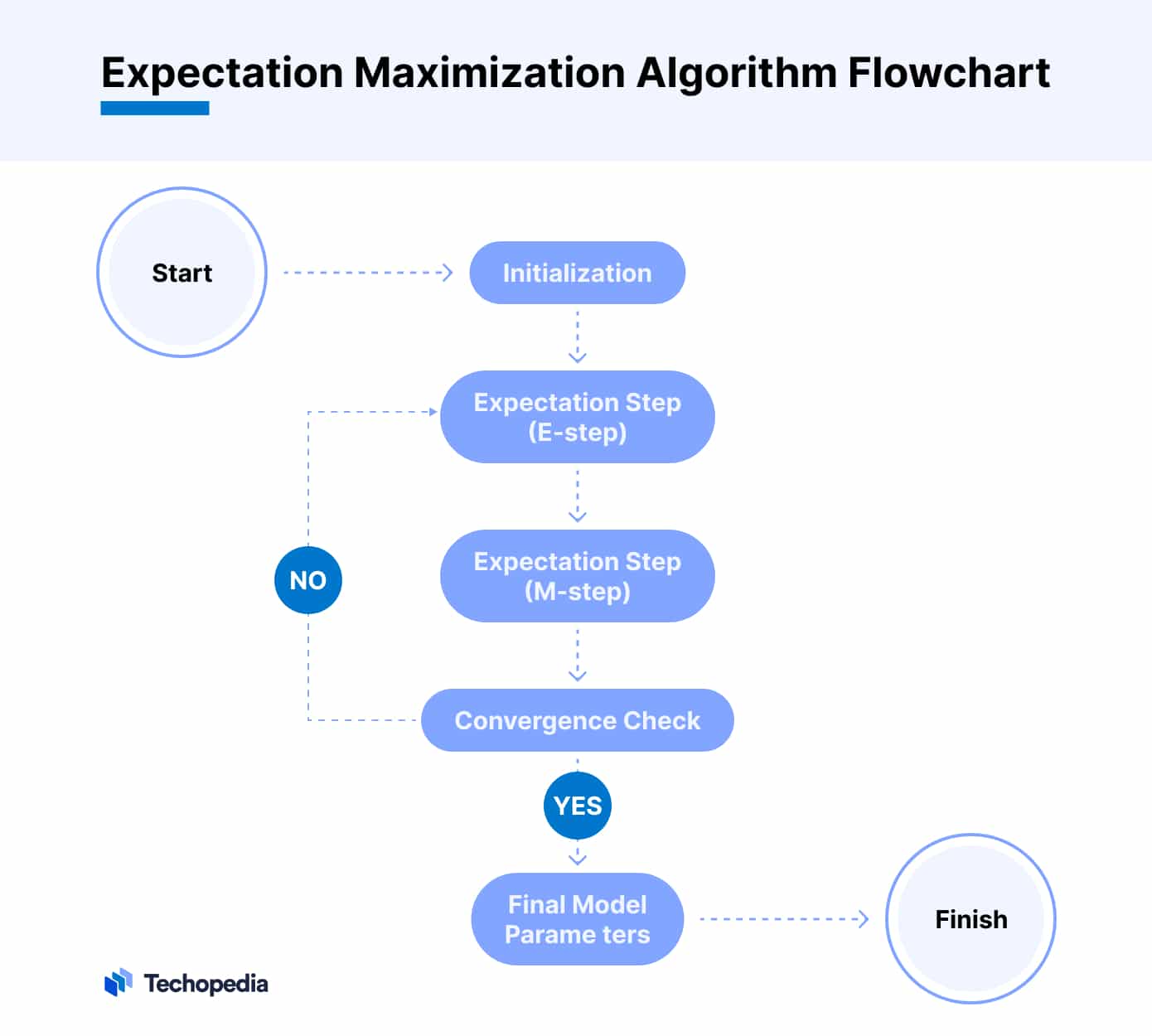
The Expectation Maximization Algorithm is a sophisticated method used in statistical analysis to find the most likely parameter estimates for models with hidden variables.
In simpler terms, it’s like a detective who iteratively gathers clues (data) and refines their hypotheses (model parameters) to solve a mystery (complete the dataset).
Let’s break down this process into two main phases: the Expectation and Maximization steps.
- Initialization: Before the EM algorithm begins, it needs initial guesses for the parameters it’s trying to estimate. These guesses can be random or based on some heuristic.
- Expectation Step (E-step): In this phase, the algorithm uses the current parameter estimates to calculate a probability distribution. This distribution represents the best guess of the hidden variables. Essentially, it creates an ‘expected’ complete data set by filling in the missing parts using the existing parameter estimates.
- Maximization Step (M-step): Now, the algorithm takes the expected data from the E-step and updates the parameters to maximize the likelihood of this ‘completed’ data. This step fine-tunes the parameters to fit the data more accurately, including the hidden part estimated in the E-step.
- Repeat: The EM algorithm cycles through these two steps, each time refining its parameter estimates based on the new information gained in the previous iteration. The process continues until the changes in the parameter estimates become negligibly small, indicating that the algorithm has converged to the most likely estimates.
Example
Let’s illustrate this using a real-world example.
Imagine you’re a teacher with a jar of mixed red and blue marbles, and you want to estimate the proportion of each color. However, students can only report the color without showing the marble.
Initially, you guess there’s an equal number of each color (this is the initialization step).
- E-step: Based on your initial guess, you calculate the expected proportions of red and blue marbles each student is likely to report.
- M-step: You then adjust your estimate of the proportions to maximize the likelihood of the students’ reported colors matching the expected proportions.
By iterating these steps, your estimates of the marble proportions become more accurate, eventually converging to the true ratio in the jar.
Key Terms in Expectation Maximization Algorithm
Understanding the Expectation Maximization algorithm requires familiarity with a few key statistical terms. These terms are the building blocks of the EM algorithm and are important for grasping how it works and why it’s useful.
| Term | Definition | Relation to EM | Importance |
| Likelihood | The probability of observing the data given a set of parameters. | In the M-step, the algorithm maximizes this likelihood to improve model fit. | Central to EM’s goal; it indicates how well the model explains the observed data. |
| Latent Variables | Variables are not directly observed but inferred from other observed variables. | EM estimates these variables in the E-step. | This is key to EM’s ability to handle incomplete data and fill in missing information. |
| Convergence | The point at which further iterations no longer significantly change the parameter estimates. | Indicates when the EM algorithm has found the most stable solution. | Signifies the end of the iterative process, ensuring the most probable parameter estimates are found. |
| Maximum Likelihood | A statistical method of estimating model parameters that maximize the likelihood function. | EM seeks to find these maximum likelihood estimates. | Provides a principled way of choosing the best model parameters. |
| Expectation Step | The step where the algorithm creates an expected data set based on current parameter estimates. | Involves calculating the expected values of the latent variables. | Sets the stage for parameter refinement, providing a ‘best guess’ of missing data. |
| Maximization Step | The step where the algorithm updates parameters to maximize the likelihood of the expected data. | Follows the E-step, refining parameters to better fit the data. | Important for iteratively improving model parameters and fitting the model to data. |
| Iterative Process | A repetitive process of performing a sequence of steps to reach a certain goal. | EM uses an iterative process of E-step and M-step to refine model parameters. | Ensures continuous improvement of the model’s fit to the data, gradually approaching the best solution. |
| Gaussian Mixture Model | A probabilistic model that assumes data points are generated from a mixture of several Gaussian distributions. | EM is often used to estimate the parameters (means, variances) of each Gaussian component in the model. | Useful in clustering and classification problems, demonstrating EM’s versatility in modeling complex data distributions. |
The Iterative Process and Theoretical Underpinnings of EM
The EM algorithm’s power lies in its iterative nature. With each cycle of E and M steps, the parameter estimates are refined, improving the model’s fit to the data.
This process continues until the algorithm converges, meaning that subsequent iterations no longer significantly change the parameters. Convergence indicates that the most likely estimates for the parameters have been found.
The mathematical foundation of the EM algorithm is grounded in probability theory and statistics. It leverages the concept of likelihood – the probability of the observed data under a particular model. By maximizing this likelihood, the algorithm seeks the parameters that make the observed data most probable.
The EM algorithm also heavily relies on the idea of latent variables. These are variables that aren’t directly observed but are important for the model’s structure. By estimating these latent variables, the EM algorithm can work with incomplete data sets.
Gaussian Mixture Model and the EM Algorithm
A Gaussian Mixture Model (GMM) is a probabilistic model that assumes data points are generated from a mixture of several Gaussian (normal) distributions, each with its own mean and variance.
This model is particularly useful in scenarios where data seems to be composed of several overlapping patterns or clusters. Think of GMM as a way of describing complex, multi-peaked data using a combination of simpler, bell-curved peaks.
The Expectation Maximization Algorithm plays a role in the effectiveness of GMMs. The challenge with GMMs is determining the parameters (means, variances, and mixture coefficients) of these Gaussian distributions when they are not known in advance.
Here’s where EM comes in:
- Initialization: The algorithm starts with initial guesses for the parameters of the Gaussian distributions.
- E-step: It calculates the likelihood of each data point belonging to each of the Gaussian distributions, based on the current parameter estimates.
- M-step: Using these likelihoods, the algorithm updates the parameters of the Gaussians to maximize the fit to the data.
By iteratively performing these steps, the EM algorithm refines the parameters of the Gaussian distributions in the mixture model until they best represent the observed data.
Benefits of Using GMM with EM in Data Analysis
Using GMMs in conjunction with the EM algorithm has several advantages in data analysis.
- Flexibility in Modeling Data: GMMs can model a wide range of data distributions, much more so than a single Gaussian distribution. This makes GMMs extremely versatile in practical applications.
- Soft Clustering: Unlike hard clustering methods that force each data point into a single cluster, GMMs allow for soft clustering. This means data points can belong to multiple clusters to varying degrees, which is more reflective of real-world data.
- Handling of Complex Datasets: GMMs, through EM, can handle complex, multi-modal datasets (data with multiple peaks) effectively, which is a challenge for many other statistical methods.
- Estimation of Hidden Variables: GMMs are adept at uncovering latent structures in the data, making them valuable in scenarios where the underlying distribution of the dataset is not apparent.
This synergy allows for more nuanced and accurate modeling of real-world data.
Example of Gaussian Mixture Model
Let’s discuss using a Gaussian Mixture Model with a practical example. Suppose we have a dataset of population heights, and we want to model this data using a GMM.
Our goal is to identify distinct subgroups within this population, such as males and females, based on their heights.
- Data Collection: We collect heights from a sample population. The data shows a range of heights with some apparent clustering.
- Initialization: We assume there are two groups (clusters) in our data (male and female heights), and we make an initial guess of the parameters (means and variances) for these two Gaussian distributions.
- Expectation Step: For each data point (height), the EM algorithm calculates the probability of it belonging to the male or female height distribution based on our current parameter estimates.
- Maximization Step: The algorithm then updates the parameters of both distributions to maximize the likelihood of the data points belonging to their respective groups. This involves adjusting the means and variances of each distribution.
- Iterate: Repeat the E-step and M-step until the parameters stabilize, indicating that the model accurately represents the data.
After several iterations, we plot the final model, which should depict two distinct bell curves (Gaussian distributions) overlaid on the histogram of our height data. One curve peaks at a shorter height range (representing females), and the other at a taller range (representing males).
Interpreting this, we can see that the GMM has successfully identified two groups in our data, corresponding to male and female heights.
The overlap between the two distributions indicates the range of heights where both male and female heights are common. The means of the distributions give us an estimate of the average height for males and females, while the variances provide insight into the variability of heights within each group.
This example demonstrates how a Gaussian Mixture Model, applied through the Expectation Maximization algorithm, can effectively identify and model hidden patterns within a dataset, providing valuable insights into its underlying structure.
Advantages and Disadvantages of EM Algorithm
The Expectation Maximization Algorithm is a powerful tool, but like all methods, it has its strengths and limitations.
| Aspect | Advantages | Disadvantages | Comparison to Other Methods |
| Handling Incomplete Data | Excellently manages incomplete or missing data, making it very effective in real-world, imperfect datasets. | – | Superior to many methods like K-means, which generally require complete data. |
| Flexibility | Highly versatile for a range of statistical models across various fields. | Dependency on initial parameter choices can lead to suboptimal solutions. | Offers more flexibility compared to simpler algorithms but may require more careful initialization. |
| Clustering Approach | Provides soft clustering with probabilistic membership, offering nuanced data interpretation. | Prone to converging to local maxima, potentially missing the best solution. | More nuanced than hard clustering methods like K-means, but potentially more complex to interpret. |
| Iterative Improvement | Iteratively refines parameter estimates, often leading to accurate models. | Computationally intensive, especially for large datasets with many parameters. | Iterative nature can be more effective than non-iterative methods but at a higher computational cost. |
| Interpretability | – | The probabilistic nature of outputs can be challenging to interpret compared to simpler models. | Offers probabilistic insights that simpler models lack, but with increased complexity in interpretation. |
Applications of Expectation Maximization
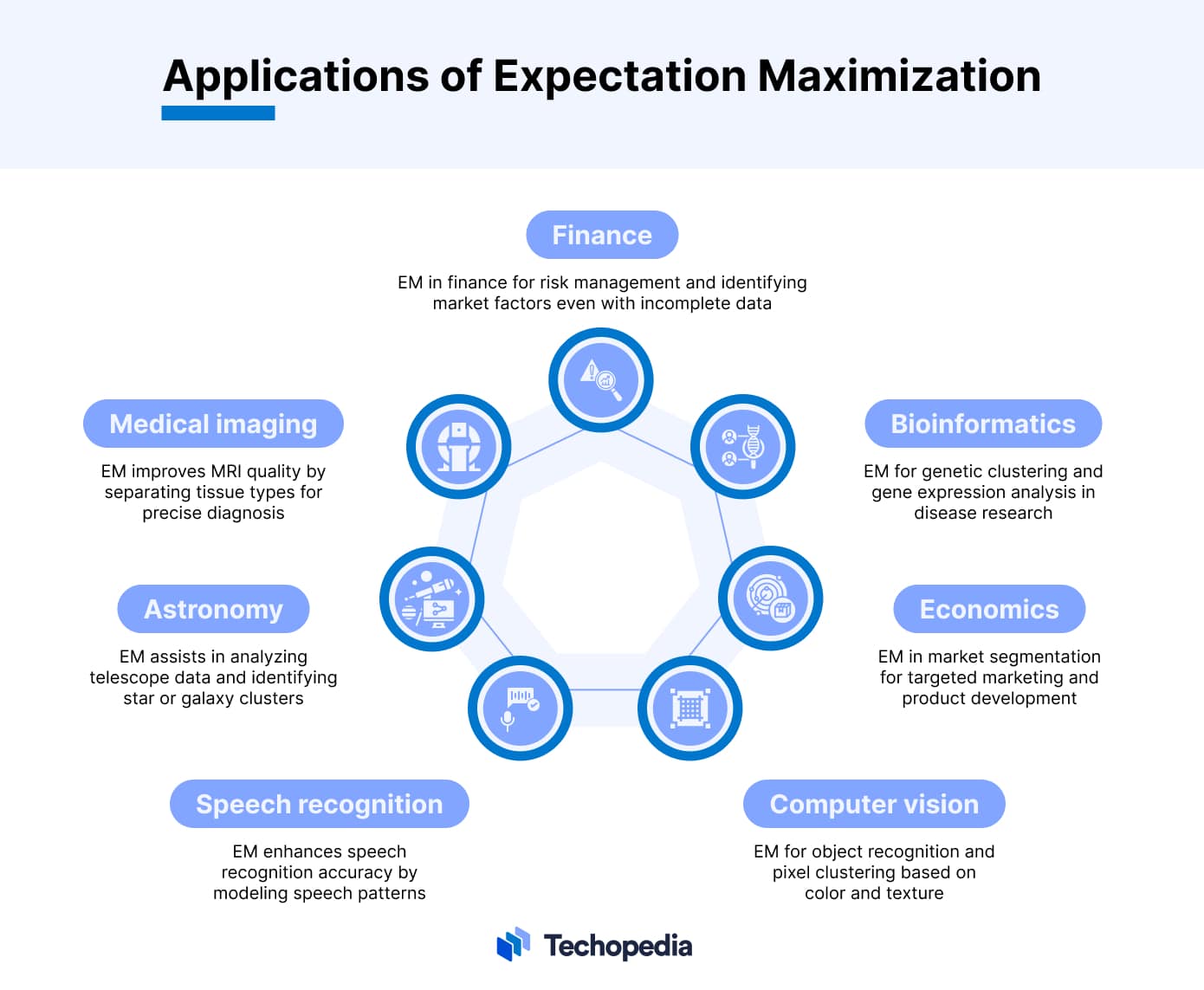 The Expectation Maximization Algorithm, due to its ability to handle incomplete data and uncover latent structures, makes it a valuable tool in complex real-world scenarios. Here are some of its applications
The Expectation Maximization Algorithm, due to its ability to handle incomplete data and uncover latent structures, makes it a valuable tool in complex real-world scenarios. Here are some of its applications
Bioinformatics
In bioinformatics, EM is used for tasks like genetic clustering and understanding evolutionary relationships.
For example, it’s applied in the analysis of gene expression data, where it helps identify clusters of genes that exhibit similar expression patterns, suggesting they may be co-regulated or functionally related. This assists researchers in understanding genetic networks and their role in diseases.
Economics
Economists use EM for market segmentation and demand analysis. By clustering consumers based on purchasing patterns or preferences, which are often incomplete or indirect, businesses can tailor marketing strategies or product development to meet specific customer needs more effectively.
Computer Vision
In computer vision, EM is employed for image analysis tasks such as object recognition and segmentation. It can, for instance, help in distinguishing different objects in an image by clustering pixels based on color and texture, even when parts of the image are obscured or missing.
Speech Recognition
In speech recognition, EM is used for modeling and recognizing speech patterns. It helps in breaking down audio into distinct phonetic components, despite the variability and noise in real-world speech, thus enhancing the accuracy of speech recognition systems.
Astronomy
Astronomers use EM for analyzing data from telescopes, where incomplete data is a common challenge. It assists in identifying clusters of stars or galaxies and estimating their properties, like mass and distance, which might not be directly measurable.
Medical Imaging
In medical imaging, EM has been used to improve the quality of MRI scans. By applying EM, radiologists can separate different tissue types in the brain, for example, even when the images are unclear or noisy. This leads to better diagnosis and understanding of brain disorders.
Finance
In finance, EM is applied in risk management and portfolio optimization. It helps identify underlying risk factors in financial markets, even with incomplete data, enabling more robust risk assessment strategies.
The Bottom Line
As we continue to generate and collect massive amounts of data, much of which is imperfect or incomplete, the importance of tools like EM remains evident. Its potential for future applications, especially in emerging technologies and complex data-driven fields, is vast.
The EM algorithm not only helps in making sense of the present data but also paves the way for future innovations in data analysis and interpretation.
With ongoing advancements in computational power and algorithmic efficiency, EM is set to remain a key tool in statistical analysis and machine learning.
FAQs
What is expectation maximization in simple terms?
What is the maximum expectation strategy?
What is expectation maximization for K clustering?
What is the difference between expectation maximization and maximum likelihood?
References
- Arthur P. Dempster (Wikipedia)
- Nan Laird (Wikipedia)
- Donald Rubin (Wikipedia)
- Maximum Likelihood from Incomplete Data via the EM Algorithm (Iastate)






















