Nowadays, no matter what artificial intelligence (AI) project we want to build, we need two main ingredients:
- A model.
- Data.
Lots of progress has been made to develop effective models—which has led AI to achieve many breakthroughs. However, equivalent work has not been conducted in the realm of data, except making data sets bigger.
While the progress towards conventional model-centric AI is making smaller differences, Andrew Ng and many other leading scientists and academics are arguing to adopt data-centric AI, which deals with the development of a new paradigm to systematically improve data quality.
Data-Centric Versus Model-Centric AI
Data-centric AI differs from model-centric AI because, in the latter, the main focus is to develop and improve models and algorithms to achieve better performance on a given task. In other words, while model-centric AI treats data as a fixed artifact and focuses on improving AI models, data-centric AI frames models as a static artifact and focus on improving data quality. (Also read: What is Data Profiling & Why is it Important in Business Analytics?)
Data is vital in AI; and adopting an approach to obtain good-quality data is crucial—because useful data is not just error-prone and limited, but also very costly to obtain.
The key idea of data-centric AI is to handle data the same way we would high-quality materials when building a house: We spend relatively more time labeling, augmenting, managing and curating the data.
Why We Need Data-Centric AI
The “mantra” of conventional model-centric AI is to optimize highly parameterized models with bigger data sets to achieve performance gains.
While this mantra works for many industries, such as media and advertising, it faces industries like healthcare and manufacturing with many challenges. These include:
- A lack of training data instances. This often leads to poor optimization and disappointing outcomes.
- A hefty bill. Existing model-centric AI requires huge data sets and expensive computer resources to provide performance gains. In comparison, data-centric AI focuses on data quality rather than quantity and does not require expensive compute resources.
- Less reliable and fair outcomes. By prioritizing data quality through a data-centric AI approach, we stand a better chance of eliminating data bias through careful analysis.
- A complex collection of models. A model-centric AI approach requires specialized models to deal with distinct tasks, which leads organizations to accumulate many data sets and many models. This also contributes to the elevated cost associated with AI: It can be difficult to afford sufficient data to deal with each little problem (such as fault detection in several different manufacturing goods).
A data-centric AI approach can help mitigate these challenges and, in turn, help organizations get more out of their data.
How to Implement Data-Centric AI
The essence of data-centric AI is to treat data as a key asset while deploying AI infrastructure.
Unlike model-centric AI, which also deals with archiving data into a repository, this paradigm emphasizes developing a shared understanding of data to maintain a uniform description.
So how we can do that? What important aspects should we consider to implement this approach? It turns out, to adopt data-centric AI, we need to follow some guidelines. They are:
1. Correct Data Labels
Data labeling, as its name suggests, deals with assigning labels to data—for example assigning disease labels to medical images.
Data labels provide crucial information about data sets, which an AI algorithm uses to learn. So, it is imperative that the information should be correct and consistent. Moreover, it has been shown that fewer well-labeled data instances (e.g., images) can produce better outcomes than more data with incorrect labels. (Also read: Why Diversity is Essential for Quality Data to Train AI.)
Data-centric AI highly emphasizes the quality of data labels, which requires dealing with inconsistencies in labels and work on labeling manuals. The best way to find these inconsistencies is to use multiple data labelers. After finding an inconsistency or ambiguity in labeling, labelers should decide how to correct the inconsistent labels and document their decision in labeling manual. It is also helpful to provide examples of correct and incorrect data labels in labeling manual.
Some examples of inconsistent labels in iguanas detection, as depicted by Andrew Ng, are shown below. Notice how the labelers are inconsistent in marking the iguanas:

 Example of inconsistent labels.
Example of inconsistent labels.
2. Remove Noisy Data Instances
You can eliminate noisy data instances by tossing them out. This expands a model’s capacity to generalize to new data.
3. Augment Data
This task involves generating more data instances from existing instances through, for example, interpolation or extrapolation.
Because data-centric AI focuses on data quality rather than quantity, but some AI models require a high volume of data to perform well, data augmentation can help you find middle ground.
It’s important to note, however, that generating more data would not help if that data contains noisy instances.
4. Feature Engineering
Feature engineering deals with representing raw data in terms of the most relevant variables (i.e., features) using prior knowledge or an algorithm.
The idea is to use domain knowledge as features to improve a predictive model’s quality instead of supplying raw data to the model. Feature engineering is vital to add extra features that may not exist in raw data but that can make a significant difference in performance and mitigate the need for collecting large data sets. (Also read: Why is feature selection so important in machine learning?)
5. Error Analysis
After training a model on a given data set, error analysis can help you find a subset of the data set to improve. By performing this process repeatedly, you can gradually improve your data’s quality and, as a result, your model’s performance.
6. Domain Knowledge
In model-centric AI, domain experts are typically not involved as data is considered to be a given artifact.
However, domain knowledge plays a vital role in data-centric AI because domain experts can often detect trivial inconsistencies in the data, which may lead to better results.
The Future of Data-Centric AI
Though most data-centric AI ideas already exist as a conventional wisdoms among AI engineers, data-centric AI aims to build a systematic approach and tools to facilitate this process. A typical life-cycle of a data-centric AI is illustrated below:
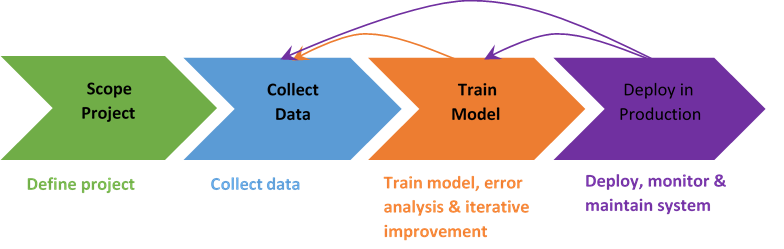
As shown in the figure, data-centric AI is an iterative process—where training analysis and deployment outcomes can result in going back to the data collection and model training phases to observe and correct issues in test data.
To help AI engineers adopt data-centric AI in their projects, the AI community has developed various tools. These include:
- LandingLens. A product developed by Landing AI, which Andrew Ng founded, LandingLens helps AI engineers develop and deploy consistent and iterative inspection systems for a wide range of tasks in a production environment. The tool consists of data, model, and deployment modules to manage data, accelerate troubleshooting, and scale to deployment.
- Cleanlab. This data-centric AI package helps clean labels, perform error analysis and learn with label errors in data sets.
- Snorkel. Snorkel is a data-centric platform which helps to programmatically label and prepare training data to accelerate the process of building and deploying machine learning models.
- AutoAugment. Developed by Google Brain, this reinforcement learning alrogithm helps increase both the amount and the diversity of data in an existing training data set. It’s also available as a Python package.
- Albumentations. This is another python library for fast and flexible image augmentations.
- HoloClean. HoloClean is designed to enable domain experts to communicate their domain knowledge in declarative way. This helps produce accurate predictions, analytics and insights from noisy, incomplete, and incorrect data.
Conclusion
Data-centric AI prioritizes data quality over quantity. Compared to model-centric AI, which seeks to engineer performance gains by expanding data sets, a data-centric approach can help mitigate many of the challenges that can arise when deploying AI infrastructure.