

















What is Edge Computing?
Edge computing is a distributed network architecture that processes data as close to the originating source as possible.
An important goal of edge computing is to minimize latency and optimize the bandwidth cost by decreasing the amount of data that needs to be transmitted over long distances. Data is typically processed on the originating device itself, on nearby network nodes, or on local servers.
Key Takeaways
- Edge computing reduces latency by processing data as close to the source as possible.
- Processing data close to the source can be cost-effective because it conserves bandwidth.
- Edge computing wasn’t practical until recent advances in technology.
- There are four main types of edge computing.
- Security is an important concern because every edge device is a potential attack surface.
How Edge Computing Works
Edge computing decentralizes data processing by allowing digital and electromechanical devices that produce data to process their own data locally. In this context, locally can mean on-device or on a nearby server or network node.
Edge computing was not practical until recently. Recent advancements in information technology (IT) that have enabled edge computing include:
- High-performance, low-power processors and system on chips (SoCs) that enable substantial computational capabilities on edge devices.
- The deployment of high-speed, low-latency 5G networks.
- Advancements in artificial intelligence (AI) and machine learning (ML) that facilitate on-device analytics and data driven decision-making (DDDM).
- The development of containerization and orchestration technologies that simplify the deployment and management of applications across diverse environments.
- Enhanced security technologies that enable zero trust.
Types of Edge Computing
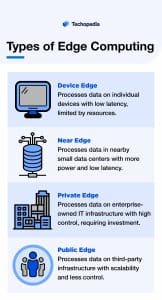
Edge computing initiatives are often categorized by the way they handle computational workloads.
Edge Computing vs. Fog Computing, MEC Computing & Cloud Computing
Now that you are familiar with edge computing’s definition, you may be wondering how fog computing and multi-access edge computing (MEC) compare. These concepts are often used interchangeably, but they have distinct differences.
While all three involve processing data closer to the source than cloud computing, they operate at different network levels and serve slightly different purposes.
Purpose: Reduce latency, conserve bandwidth, and enable on-device processing.
Use Cases: Best for applications that need to process data immediately.
Connectivity: Does not rely on Internet connectivity.
Purpose: Aggregate and filter data from multiple edge devices before sending relevant information to the cloud.
Use Cases: Best for applications that can process data on local servers or network nodes.
Connectivity: Requires Internet connectivity at some point.
Purpose: Provide mobile users with real-time access to network and cloud resources.
Use Cases: Best for mobile applications that require ultra-low latency and high bandwidth.
Connectivity: Relies on cellular infrastructure for Internet connectivity.
Edge Computing Use Cases
Edge computing is increasingly being used in many industries and market segments to enhance operational efficiency and support decision-making capabilities in real time.
Arguably, the three most important use cases that are driving data processing at the network edge are:
- The need to process data in real-time.
- The need to process data produced by thousands of Internet of Things (IoT) devices as inexpensively as possible.
- The need for increased device autonomy in remote or disconnected environments.
Edge Computing Examples
Here are some examples that illustrate how edge computing is being used to reduce latency and enable real-time decision-making across various industries and applications:
When manufacturing plants use edge computing, advanced electromechanical equipment can schedule their own maintenance autonomously.
Importance of Security at the Edge
Security plays an important role in edge computing because the distributed network architecture expands the attack surface for cyberthreats.
Each edge device needs to be supported by network security protocols that can detect and mitigate zero day threats locally to minimize the risk that one compromised device could jeopardize an entire network.
The physical security of edge devices is also a significant concern.
To prevent physical tampering or theft, it’s important to implement stringent security measures that can verify the integrity of the device’s firmware and software. Password managers can be used to securely store and manage complex credentials for accessing edge devices.
Edge Computing and Data Privacy
Data privacy is another important concern for organizations that allow data to be processed at the edge.
When sensitive data is processed close to its source, it reduces the amount of data that needs to be transmitted to centralized or distributed data centers. However, it also means that sensitive information will be managed by edge devices that could be compromised.
Access controls with authentication mechanisms should be used to ensure that only authorized personnel and systems can access sensitive or personally identifiable information (PII) that is processed and/or stored on edge devices.
Edge Computing Pros and Cons
While edge computing offers significant benefits in terms of reducing latency, using bandwidth efficiently, and making decisions in real time, it also presents challenges related to cybersecurity and data privacy that need to be carefully managed.
Pros
- Faster response times
- Reduced network congestion
- Permits autonomous data-driven decisions
Cons
- Increased attack surface
- Requires stringent device management policies.
- Requires edge computing implementations to comply with relevant data protection regulations.
The Bottom Line
Edge computing’s meaning and use cases have evolved as technology has advanced and the demand for real-time data processing and low-latency applications has increased.
Today, edge computing can provide significant advantages in terms of reduced latency and bandwidth efficiency; however, its implementation requires careful planning and consideration of factors like hardware selection, security, and regulatory compliance.
Organizations need to carefully evaluate their specific use cases, infrastructure, and resources to determine if the benefits of edge computing outweigh these challenges.




















