What is GraphQL?
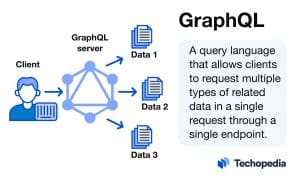
GraphQL is an open source query language (QL) and server-side runtime that allows clients in a client/server architecture to request multiple types of related data in a single request through a single endpoint. GraphQL ‘s most common use case is for querying application programming interfaces (APIs).
The GraphQL specification is managed by the GraphQL Foundation, which is hosted by the Linux Foundation. The foundation’s involvement helps ensure that GraphQL continues to be developed in a vendor-neutral environment, with input from a broad set of companies and individual contributors.
Techopedia Explains the GraphQL Meaning
GraphQL definition often begins by explaining how the terms graph and query language are used in computing. Each term provides insight into what GraphQL is and how it works.
- A graph is used to visualize data relationships.
- A query language (QL) is used to request and retrieve data.
The “graph” in GraphQL refers to the idea that data is interconnected and can be explored through the connections. The “QL” aspect of GraphQL’s meaning explains the mechanism by which the related data is explored and retrieved.
GraphQL History
In 2012, Facebook software engineers became frustrated with the way APIs built with representational state transfer (REST) architectures were degrading the performance of Facebook news feeds on mobile devices.
Sometimes the RESTful APIs returned too much data, and sometimes, they didn’t return enough data and had to make additional API calls (requests for data.)
To improve performance, Facebook developers created a new architecture that reduced unnecessary data transfers and provided a better user experience (UX). They named the specification for the new architecture GraphQL.
In 2015, Facebook decided to make GraphQL open source. This allowed developers outside Facebook to use and contribute to GraphQL’s evolution. It also inspired the developer community at large to rethink how they were writing and using APIs.
How GraphQL Works
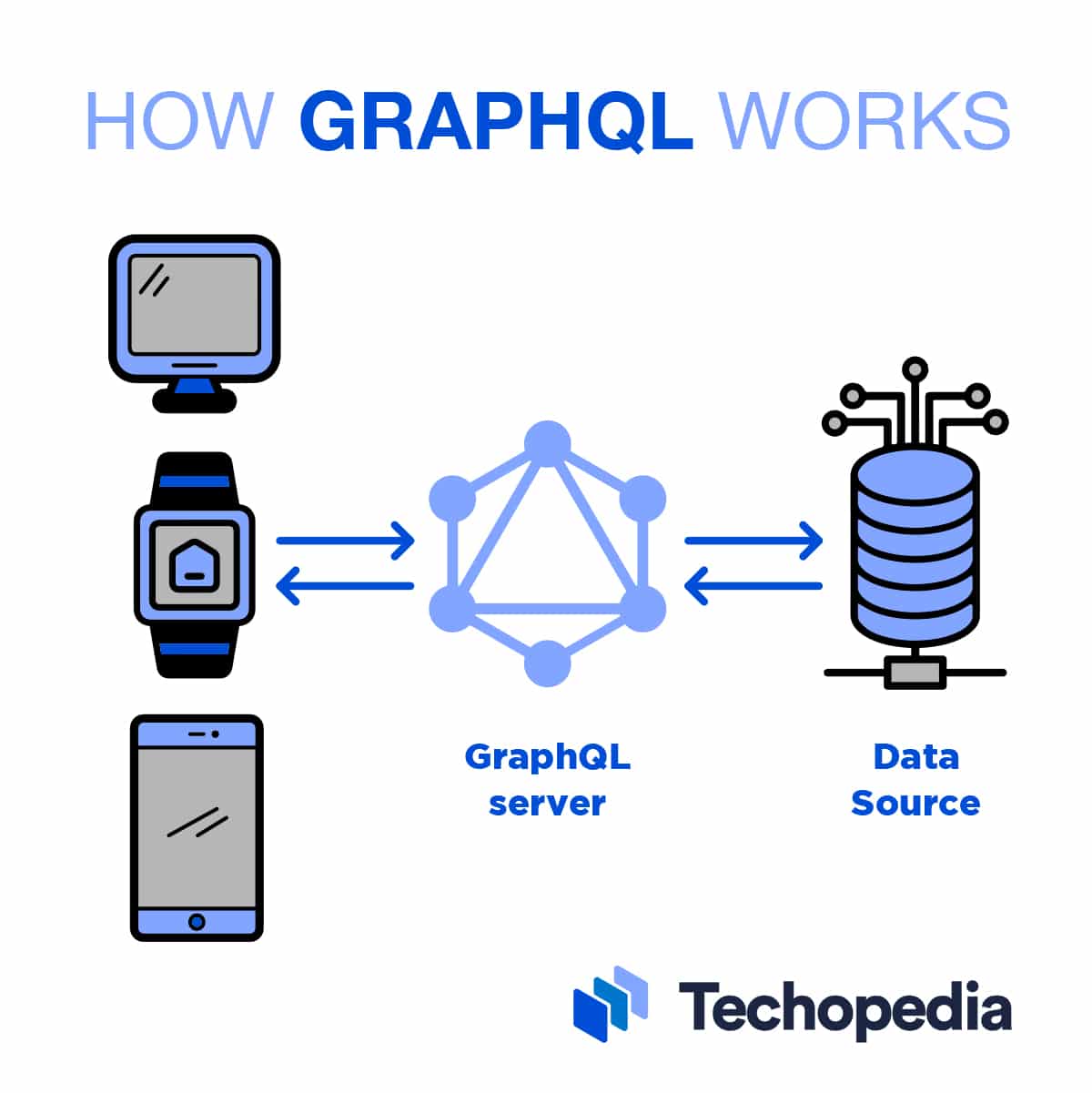
To use GraphQL, software developers need to create a GraphQL server, define the schema they want to use, and write resolvers (functions) that can locate the requested data, retrieve it, and return it to the client.
The schema acts like a contract between the server and the client. It specifies what types of query the client can make, what types of data structures can be requested, and what operations (interactions) the server supports.
The server provides an endpoint where clients can send their GraphQL queries and receive the corresponding responses. The server’s runtime processes the query, invokes resolvers, aggregates the responses, and sends them back to the client in one JavaScript Object Notation (JSON) response.
GraphQL Features
GraphQL features allow developers and clients to:
- Query schema to learn what types of queries are supported.
- Retrieve different types of data in the same query.
- Receive the exact data that’s requested.
- Subscribe to news feeds and receive updates in real time through technologies like WebSockets.
- Receive server errors in the context of the data they relate to.
- Use GraphQL and REST APIs in the same application.
- Introduce GraphQL incrementally by replacing specific REST endpoints over time.
GraphQL API vs. Rest API
RESTful APIs and GraphQL APIs serve similar purposes, but they work quite differently. Here is a very high-level view of their differences:
RESTful APIs
RESTful API architectures are focused on server resources, which are different types of data like /users, /posts, /orders. Each resource is assigned a unique universal resource locator (URL).
The architecture also requires clients to interact with resources in very specific ways. To get data from two different resources, for example, the API has to send requests to two different URLs on the server.
This approach works well for apps that need to retrieve a limited amount of data to populate an update, but it doesn’t work well for news feeds and other types of apps that need to interact with hundreds of resources to populate an update.
To complicate things, sometimes a resource will have the data the client needs, but sometimes it won’t have ALL the required data, and the API will need to send out additional requests to other URLs.
All that back-and-forth client/server communication uses up bandwidth and can significantly slow down the client’s performance.
GraphQL APIs
GraphQL APIs significantly reduce the number of client/server interactions required to fulfill requests for related data.
GraphQL APIs require the client to specify what data it needs and then send a single query to a single endpoint (the GraphQL server). Software on the server locates the requested data, assembles it into one reply, and returns the requested data to the client.
This sounds like a very simple process, but it requires more setup behind the scenes on the server-side to work.
Developers need to design a schema that maps to existing data sources and define resolvers that know how to fetch data from them. They also need to implement logic to handle potential errors and optimize data retrieval, and create policies that will enforce authorization rules within resolvers.
GraphQL Use Cases
GraphQL is useful for efficiently retrieving data from diverse, distributed data sources. It is well-suited for:
- Querying APIs.
- Retrieving data from multiple databases, microservices, and/or APIs.
- Populating mobile news feeds that provide live updates.
- Allowing e-commerce website visitors to add filters to their search queries.
- Supporting Internet of Things (IoT) hubs that need to fetch specific data points across a network of connected devices.
- Streamlining front-end development by taking the guesswork out of what the API will return.
What are GraphQL Supergraphs?
A supergraph combines multiple GraphQL schemas/subgraphs into a single, unified GraphQL API.
GraphQL supergraphs aggregate multiple GraphQL APIs into a single, unified API with one endpoint. The supergraph hides the complexity of distributed data schemes, and makes it easier for front end developers to work with complex distributed data structures.
Supergraphs are useful for:
- Consolidating APIs for multiple microservices.
- Gradually introducing GraphQL to older systems.
- Combining GraphQL APIs from different companies or systems that are involved in a merger.
- Breaking down a monolithic GraphQL schema into smaller, more manageable subgraphs and aggregating them into a single query.
Incorporating large language model (LLM) capabilities into an existing GraphQL API.
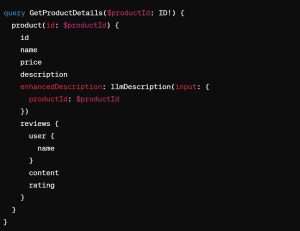
Supergraph GraphQL Example
This is what the query might look like.
When this query is submitted, the GraphQL Supergraph engine will:
- Fetch basic product information from the products subgraph.
- Concurrently, request an enhanced description from the LLM subgraph.
- Fetch user reviews, including details from the user subgraph.
- Compile all these data points into a single, coherent response and send it back to the client.
GraphQL Pros and Cons
GraphQL offers significant advantages in terms of flexibility and efficiency for developers who are working with complex applications that have diverse data needs.
It can be challenging to set up, however, and it’s not necessarily the best choice for every scenario. REST can be a more efficient choice for applications with straightforward data retrieval needs.
The decision to use GraphQL should be based on the specific needs of the application and consider factors like the complexity of data relationships, the importance of client-side control over data fetching, the frequency of queries that require data from multiple sources, and the development team’s familiarity with GraphQL.
Pros
- Conserves bandwidth
- Streamlines API calls
- Facilitates auto-generated documentation
- Supports subscriptions for live feeds and other apps that refresh data in real time
- Enables frontend teams to make changes to data requests without impacting back end logic
Cons
- Server-side set up is complex
- There can be a high learning curve for backend developers
- Tooling might not be as mature in some areas compared to REST
The Bottom Line
GraphQL is a query language and runtime that is particularly well-suited for applications that require efficient data retrieval for different types of related data in real time. Its adoption should be considered in the context of the specific needs of an application, the complexity of the data involved, and the technical capabilities of the development team.
FAQs
What is GraphQL in simple terms?
What is the difference between GraphQL and Rest API?
Is GraphQL backend or frontend?
Is GraphQL just SQL?
References
- What is the GraphQL Foundation? (Graphql)
- Linux Foundation – Decentralized innovation, built with trust (Linuxfoundation)
- A Brief History of GraphQL – DEV Community (Dev)
- The supergraph: a new way to think about GraphQL | Apollo GraphQL Blog (Apollographql)